
Innføring av tekstgruvedrift
Text Mining - I dagens kontekst er tekst de vanligste virkemidlene som utveksles informasjon gjennom. Men å forstå meningen fra teksten er ikke en lett jobb i det hele tatt. Vi trenger et godt forretningsinformasjonsverktøy som vil hjelpe deg med å forstå informasjonen på en enkel måte.
Hva er tekstgruvedrift
Text Mining er også kjent som Text Analytics. Det er prosessen med å forstå informasjon fra et sett tekster. Text Mining er designet for å hjelpe virksomheten med å finne ut verdifull kunnskap fra tekstbasert innhold. Dette innholdet kan være i form av orddokument, e-post eller innlegg på sosiale medier.
Text Mining er bruk av automatiserte metoder for å forstå kunnskapen som er tilgjengelig i tekstdokumentene.
Text Mining kan også brukes for å få datamaskinen til å forstå strukturerte eller ustrukturerte data. Kvalitative data eller ustrukturerte data er data som ikke kan måles i antall. Disse dataene inneholder vanligvis informasjon som farge, tekstur og tekst. Kvantitative data eller strukturerte data er data som enkelt kan måles.
Tekstbryting er et tverrfaglig felt som inkluderer innhenting av informasjon, gruvedrift av data, maskinlæring, statistikk og andre. Text Mining er et litt annet felt enn data mining.
Fordeler med tekstgruvedrift
Det er mange fordeler med å bruke Text Mining. De er listet opp nedenfor
- Det sparer tid og ressurser og yter effektiv enn menneskelige hjerner.
- Det hjelper å spore meninger over tid
- Text Mining hjelper deg med å oppsummere dokumentene
- Tekstanalyse hjelper til med å trekke ut konsepter fra tekst og presentere det på en enklere måte
- Teksten som indekseres ved bruk av Text mining kan brukes i prediktiv analyse
- Du kan koble til eventuelle vokabularer for å bruke terminologien i ditt interesseområde
Bruk av tekstgruvedrift
- Navnene på forskjellige enheter og forhold mellom teksten kan enkelt finnes ved bruk av forskjellige teknikker.
- Det hjelper til med å trekke ut mønstre fra store mengder ustrukturerte data
- Systematisk gjennomgang av litteratur - Det kan gå til dybdeforskning av tekst, finne ut sentrale temaer og fremheve de gjentatte begrepene eller teksten og de populære emnene over en periode.
- Testing av hypotese - Gjennom tekstbryting kan en bestemt hypotese testes for å se om dokumentet bekrefter eller avviser hypotesen. Det meste testes en etablert tro først over dokumentet.
Utvikle løsninger på forretningsproblemer effektivt. Lær å definere, analysere og dokumentere forretningskrav. Undersøk forretningsaktiviteter for å gjøre dem mer effektive.
Betydningen av tekstgruvedrift
- Text Mining er muliggjør bedre og smart beslutningstaking
- Det hjelper til med å løse kunnskapsoppdagelsesproblemer i forskjellige virksomhetsområder
- Gjennom tekstbryting kan du enkelt visualisere dataene på mange måter som html-tabeller, diagrammer, grafer og andre
- Det er et flott produktivitetsverktøy. Det gir bedre resultater raskere enn noe annet verktøy.
- Tekstgruveverktøy brukes av både store og små organisasjoner som er kunnskapsdrevne organisasjoner.
Bruksområder for Text Mining
-
Analysere svar fra åpen undersøkelse
Spørsmål om åpent sluttundersøkelse vil hjelpe respondentene til å gi sitt syn eller mening uten noen begrensninger. Dette vil bidra til å vite mer om kundenes meninger enn å stole på strukturerte spørreskjemaer. Tekstbryting kan brukes til å analysere slik informasjon i form av tekst.
-
Automatisk behandling av meldinger, e-post
Text Mining brukes også hovedsakelig til å klassifisere teksten. Text Mining kan brukes til å filtrere unødvendig e-post ved hjelp av visse ord eller uttrykk. Slike e-poster vil automatisk kaste slike e-poster til spam. Et slikt automatisk system for klassifisering og filtrering av valgte post og sending av den korresponderende avdelingen gjøres ved hjelp av Text Mining-system. Text Mining vil også sende et varsel til e-postbrukeren om å fjerne postene med slike krenkende ord eller innhold.
-
Analyse av garanti- eller forsikringskrav
I de fleste forretningsorganisasjoner samles informasjon hovedsakelig i form av tekst. For eksempel på et sykehus kan pasientintervjuene fortelles kort i tekstform, og rapportene er også i form av tekst. Disse notatene er nå samlet inn en dag elektronisk, slik at de enkelt kan overføres til algoritmer for tekstbryting. Disse postene kan deretter brukes til å diagnostisere den faktiske situasjonen.
-
Undersøk konkurrenter ved å gjennomsøke nettstedene deres
Et annet viktig applikasjonsområde for Text Mining er å behandle innholdet på websider i et bestemt domene. På denne måten vil tekstgruvesystemet automatisk finne en liste over begrep som brukes på nettstedet. Gjennom denne måten kan man finne ut de viktigste begrepene som brukes på nettstedet. På denne måten kan man kjenne til mulighetene om konkurrentene som kan hjelpe deg med å levere virksomheten effektivt.
De andre applikasjonene av Text Mining inkluderer følgende
- Business Intelligence
- E Oppdagelse
- bioinformatikk
- Registeradministrasjon
- Nasjonal sikkerhet eller etterretning fungerer
- Overvåking av sosiale medier
Teknikker brukt i tekstgruvedrift
Det er fem grunnleggende teknologier som brukes i Text Mining-systemet. De blir diskutert i detalj nedenfor
-
Informasjon utvinning
Dette brukes til å analysere den ustrukturerte teksten ved å finne ut de viktige ordene og finne sammenhengene mellom dem. I denne teknikken brukes prosessen med mønstermatching for å finne ut rekkefølgen i teksten. Det hjelper med å transformere den ustrukturerte teksten til strukturert form. Informasjonsutvinningsteknikken innebærer språkbehandlingsmoduler. Dette brukes mest der det er store datamengder. Prosessen med utvinning av informasjon blir forklart på bildet nedenfor.
-
kategorisering
Kategoriseringsteknikk klassifiserer tekstdokumentet under en eller flere kategorier. Det er basert på eksempler på input for å gjøre klassifiseringen. Kategoriseringsprosessen inkluderer forbehandling, indeksering, dimensjonsreduksjon og klassifisering. Teksten kan kategoriseres ved hjelp av teknikker som Naive Bayesian klassifiserer, Decision tree, Nærmeste nabo-klassifiserer og Support Vendor Machines.
-
Gruppering
Clustering-metoden brukes til å gruppere tekstdokumenter som har lignende innhold. Den har partisjoner kalt klynger, og hver partisjon vil ha et antall dokumenter med lignende innhold. Clustering sørger for at ikke noe dokument blir utelatt fra søket, og at det stammer alle dokumentene som har lignende innhold. K-middel er den ofte brukte klyngeteknikken. Denne teknikken sammenligner også hver klynge og finner hvor godt dokumentet er koblet til hverandre. Bedrifter bruker denne teknikken for å lage en database med tusenvis av lignende dokumenter.
-
visualisering
Visualiseringsteknikk brukes for å forenkle prosessen med å finne relevant informasjon. Denne teknikken bruker tekstflagg for å representere dokumenter eller gruppe av dokumenter og bruker farger for å indikere kompaktheten. Visualiseringsteknikk er med på å vise tekstinformasjon på en mer attraktiv måte. Bildet nedenfor vil representere Visualiseringsteknikken
-
samandrag
Oppsummeringsteknikk vil bidra til å redusere lengden på dokumentet og oppsummere detaljene i dokumentene i korte trekk. Det får dokumentet til å lese for brukerne og forstå innholdet på et øyeblikk. Oppsummering erstatter hele settet med dokumenter. Det oppsummerer stort tekstdokument enkelt og raskt. Mennesker tar mer tid å lese og deretter oppsummere dokumentet, men denne teknikken gjør det veldig raskt. Det hjelper med å løfte frem viktige punkter i et dokument. Oppsummeringsprosessen er representert på bildet nedenfor.
Metoder og modeller brukt i tekstgruvedrift
Basert på innhenting av informasjon Text Mining har fire hovedmetoder
-
Termbasert metode (TBM)
Begrep i et dokument betyr et ord som har semantisk betydning. I denne metoden analyseres hele settet med dokumenter på bakgrunn av termin. En hovedulempe med denne metoden er problemet med synonym og polysemi. Synonyme er der flere ord som har samme betydning. Polysemi er der et enkelt ord har flere betydninger.
-
Setningsbasert metode (PBM)
I denne metoden analyseres dokumentet basert på setningene som er mindre åpenbare for mer betydning og mer diskriminerende. Ulempene med denne metoden inkluderer
- De har dårligere statistiske egenskaper til termer
- De har lav forekomst
- De har stort antall støyende uttrykk
-
Konseptbasert metode (CBM)
I denne metoden analyseres dokumentet basert på setnings- og dokumentnivå. I denne metoden er det tre hovedkomponenter. Den første komponenten undersøker den meningsfulle delen av setningene. Den andre komponenten produserer en konseptuell ontologisk graf for å forklare strukturene. Den tredje komponenten trekker ut toppkonsepter basert på de to første komponentene. Denne metoden kan skille mellom viktige og uviktige ord.
-
Pattern Taxonomy Method (PTM)
I denne metoden analyseres dokumentet basert på mønstrene. Mønstre i et dokument kan bli funnet ut ved bruk av data mining-teknikker som gruvedrift av tilknytningsregel, sekvensiell mønsterutvinning, hyppig gruvedrift av gjenstander og gruvedrift av lukket mønster. Denne metoden bruker to prosesser - mønsterutplassering og mønsterutvikling. Denne metoden er bevist å prestere bedre enn alle andre modeller eller metoder.
Hvordan fungerer Text Mining
Nå skulle du ha forstått at tekstbryting gjør det mulig å forstå teksten bedre enn noe annet. Text Mining-systemet lager en ordveksling fra ustrukturerte data til numeriske verdier. Tekstbryting er med på å identifisere mønstre og forhold som eksisterer i en stor mengde tekst. Tekstbryting bruker ofte beregningsalgoritmer for å lese og analysere tekstinformasjon. Uten tekstbryting vil det være vanskelig å forstå teksten enkelt og raskt. Tekst kan utvinnes på en mer systematisk og omfattende måte, og informasjonen om virksomheten kan fanges automatisk. Trinnene i prosess for gruvedrift av tekst er listet nedenfor.
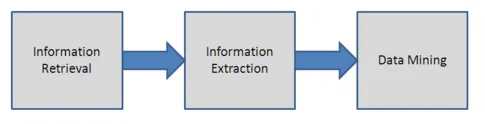
-
Trinn 1: Innhenting av informasjon
Dette er det første trinnet i prosessen med data mining. Dette trinnet innebærer hjelp av en søkemotor for å finne ut samlingen av tekst også kjent som korpus av tekster som kan trenge en viss konvertering. Disse tekstene skal også bringes sammen i et bestemt format som vil være nyttig for brukerne å forstå. Vanligvis er XML standarden for tekstbryting
-
Trinn 2: Natural Language Processing
Dette trinnet gjør at systemet kan utføre grammatisk analyse av en setning for å lese teksten. Den analyserer også teksten i strukturer.
-
Trinn 3: Utvinning av informasjon
Dette er det andre trinnet for å identifisere betydningen av en bestemt tekstmarkering. I dette stadiet legges det til en metadata i databasen om teksten. Det innebærer også å legge til navn eller lokasjoner i teksten. Dette trinnet lar søkemotoren få informasjonen og finne ut forholdene mellom tekstene ved hjelp av metadataene deres.
-
Trinn 4: Datamining
Det siste stadiet er data mining med forskjellige verktøy. Dette trinnet finner likhetene mellom informasjonen som har samme betydning som ellers vil være vanskelig å finne. Text Mining er et verktøy som øker forskningsprosessen og hjelper til med å teste spørsmålene.
Text Mining inkluderer følgende liste over elementer
- Tekstkategorisering
- Tekstklynging
- Konsept / enhet utvinning
- Granulære taksonomier
- Sentiment Analyse
- Dokumentoppsummering
- Modellering av enhetens forhold
Utfordringer med tekstgruvedrift
Den viktigste utfordringen med Text Mining-systemet er det naturlige språket. Det naturlige språket står overfor problemet med tvetydighet. Tvetydighet betyr ett begrep som har flere betydninger, hvor en frase blir tolket på forskjellige måter, og som et resultat oppnås forskjellige betydninger.
En annen begrensning er at mens du bruker informasjonsekstraksjonssystem, innebærer det semantisk analyse. På grunn av dette presenteres ikke fullteksten, bare en begrenset del av teksten blir presentert for brukerne. Men i disse dager er det behov for mer tekstforståelse.
Text Mining har også begrensninger med lov om opphavsrett. Det er mange begrensninger i tekstutvinning av et dokument. De fleste av gangene inkluderer det rettighetene til rettighetshaverne. De fleste tekstene vil ikke bli funnet som åpen kildekode, og i slike tilfeller kreves tillatelse fra de respektive forfattere, utgivere og andre nærstående parter.
En ytterligere begrensning er at tekstbryting ikke genererer nye fakta, og det er ikke en sluttprosess.
Konklusjon
Tekstbryting eller tekstanalyse er en blomstrende teknologi, men fortsatt varierer resultatene og analysedypen fra virksomhet til virksomhet. En organisasjon kan bruke tekstbryting for å få kunnskap om innholdsspesifikke verdier.