
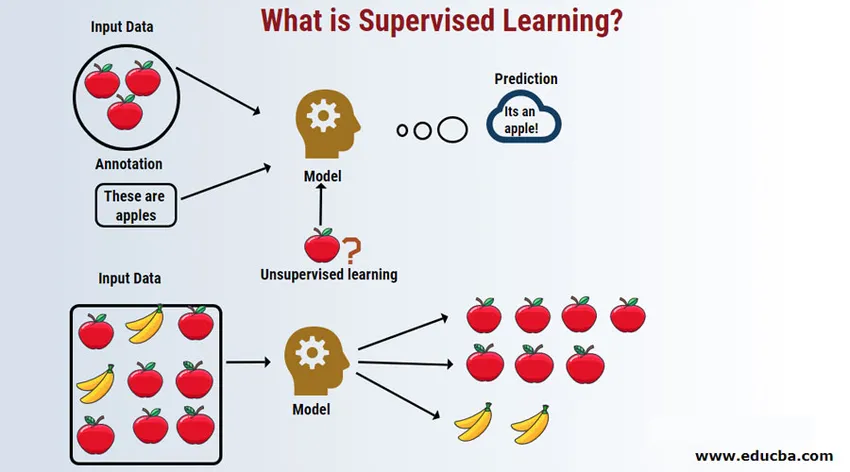
Introduksjon til veiledet læring
Supervised Learning er et område med maskinlæring der vi jobber med å forutsi verdiene ved bruk av merkede datasett. De merkede inndatasettene kalles den uavhengige variabelen, mens de forutsagte resultatene kalles den avhengige variabelen fordi de er avhengige av den uavhengige variabelen for resultatene. For eksempel har vi alle spam-mapper i e-postkontoen vår (for eksempel Gmail), som automatisk oppdager det meste av spam- / svindel-e-postmeldinger for deg med nøyaktighet over 95%. Det fungerer basert på en overvåket læringsmodell der vi har et opplæringssett med merkede data, som i dette tilfellet er merket spam e-post som er flagget av brukere. Disse opplæringssettene brukes til læring som senere vil bli brukt til kategorisering av nye e-postmeldinger som spam hvis det passer kategorien.
Jobber med veiledet maskinlæring
La oss forstå veiledet maskinlæring ved hjelp av et eksempel. La oss si at vi har fruktkurv som er fylt opp med forskjellige fruktarter. Jobben vår er å kategorisere frukt basert på kategorien deres.
I vårt tilfelle har vi vurdert fire typer frukt, og de er eple, banan, druer og appelsiner.
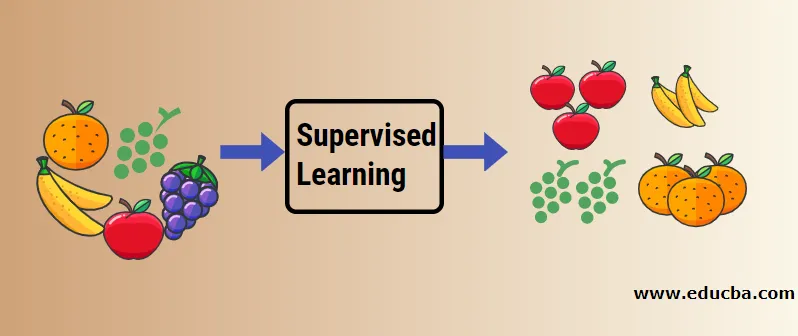
Nå skal vi prøve å nevne noen av de unike egenskapene til disse fruktene som gjør dem unike.
|
S Nei. | Størrelse | Farge | Form |
Fornavn |
|
1 | Liten | Grønn | Rund til oval, sylindrisk bunkeform |
Drue |
|
2 | Stor | rød | Avrundet form med en depresjon øverst |
eple |
|
3 | Stor | Gul | Lang buet sylinder |
Banan |
| 4 | Stor | oransje | Avrundet form |
oransje |
La oss nå si at du har hentet en frukt fra fruktkurven, du har sett på dens funksjoner, for for eksempel form, størrelse og farge for eksempel, og deretter trekker du ut at fargen på denne frukten er rød, størrelsen hvis den er stor, formen er avrundet form med depresjon på toppen, og dermed er det et eple.
- På samme måte gjør du det samme for alle andre gjenværende frukter også.
- Den høyre kolonnen ("Fruit Name") er kjent som responsvariabelen.
- Slik formulerer vi en veiledet læringsmodell, nå vil det være ganske enkelt for noen nye (La oss si en robot eller en romvesen) med gitte egenskaper for enkelt å gruppere samme type frukt sammen.
Typer veiledet maskinlæringsalgoritme
La oss se forskjellige typer maskinlæringsalgoritmer:
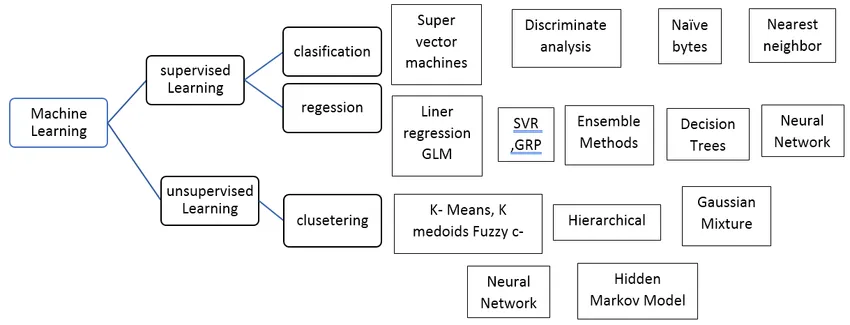
regresjon:
Regresjon brukes til å forutsi output av en verdi ved å bruke treningsdatasettet. Utgangsverdien kalles alltid som den avhengige variabelen mens inngangene er kjent som den uavhengige variabelen. Vi har forskjellige typer regresjon i Supervised Learning, for eksempel,
- Lineær regresjon - Her har vi bare en uavhengig variabel som brukes til å forutsi utgangen dvs. avhengig variabel.
- Multiple Regression - Her har vi mer enn en uavhengig variabel som brukes til å forutsi output, dvs. den avhengige variabelen.
- Polynomial regression - Her følger grafen mellom de avhengige og uavhengige variablene en polynomfunksjon. For f.eks først øker minnet med alderen, så når det en terskel i en viss alder, og så begynner det å avta når vi blir gamle.
Klassifisering:
Klassifiseringen av veiledede læringsalgoritmer brukes til å gruppere lignende objekter i unike klasser.
- Binær klassifisering - Hvis algoritmen prøver å gruppere 2 forskjellige grupper av klasser, kalles den binær klassifisering.
- Multiklassklassifisering - Hvis algoritmen prøver å gruppere objekter til mer enn to grupper, kalles det flerklasseklassifisering.
- Styrke - Klassifiseringsalgoritmer fungerer vanligvis veldig bra.
- Ulemper - utsatt for overdreven montering og kan være ubegrenset. For eksempel - E-post spam klassifiserer
- Logistisk regresjon / klassifisering - Når Y-variabelen er en binær kategorisk (dvs. 0 eller 1), bruker vi Logistisk regresjon for prediksjonen. For eksempel - Å forutsi om en gitt kredittkorttransaksjon er svindel eller ikke.
- Naïve Bayes klassifiserere - Naïve Bayes klassifiserer er basert på det Bayesiske teorem. Denne algoritmen er vanligvis best egnet når dimensjonaliteten til inngangene er høy. Den består av sykliske grafer som har en foreldre og mange barneknuter. Barnetodene er uavhengige av hverandre.
- Beslutningstrær - Et beslutnings tre er et trekartlignende struktur som består av en intern node (test på attributt), gren som angir utfallet av testen og bladknutene som representerer fordelingen av klasser. Rotknoden er den øverste noden. Det er en veldig mye brukt teknikk som brukes til klassifisering.
- Support Vector Machine - En støttevektormaskin er eller en SVM gjør jobben med klassifisering ved å finne hyperplanet som skal maksimere margen mellom 2 klasser. Disse SVM-maskinene er koblet til kjernefunksjonene. Felt, der SVM-er er mye brukt, er biometri, mønstergjenkjenning, etc.
Fordeler
Nedenfor er noen av fordelene med veiledte maskinlæringsmodeller:
- Ytelsen til modeller kan optimaliseres av brukeropplevelsene.
- Veiledet læring gir resultater ved bruk av tidligere erfaring og lar deg også samle inn data.
- Overvåkede maskinlæringsalgoritmer kan brukes til å implementere en rekke reelle problemer.
ulemper
Ulempene med veiledet læring er som følger:
- Arbeidet med å trene veiledte modeller for maskinlæring kan ta mye tid hvis datasettet er større.
- Klassifiseringen av big data gir noen ganger en større utfordring.
- Man må kanskje håndtere problemene med å overmontere.
- Vi trenger mange gode eksempler hvis vi vil at modellen skal prestere bra mens vi trener klassifiseringen.
God praksis mens du bygger læringsmodeller
Det er en god praksis når du bygger en Supervised Learning Machine Models: -
- Før du bygger en god maskinlæringsmodell, må prosessen med forbehandling av data utføres.
- Man må bestemme algoritmen som skal være best egnet for et gitt problem.
- Vi må bestemme hvilken type data som skal brukes til treningssettet.
- Trenger å bestemme strukturen til algoritmen og funksjonen.
Konklusjon
I vår artikkel har vi lært hva som er veiledet læring, og vi så at her trener vi modellen ved hjelp av merkede data. Så gikk vi inn i arbeidet med modellene og deres forskjellige typer. Vi så til slutt fordelene og ulempene med disse veiledede maskinlæringsalgoritmene.
Anbefalte artikler
Dette er en guide til hva som er Supervised Learning ?. Her diskuterer vi begrepene, hvordan det fungerer, typer, fordeler og ulemper ved Supervised Learning. Du kan også gå gjennom andre foreslåtte artikler for å lære mer -
- Hva er dyp læring
- Veiledet læring vs dyp læring
- Hva er synkronisering i Java?
- Hva er webhotell?
- Måter å lage beslutningstreet med fordeler
- Polynomial regresjon | Bruksområder og funksjoner