

Forskjellen mellom Hadoop og Hive
Hadoop:
Hadoop er et rammeverk eller programvare som ble oppfunnet for å administrere enorme data eller Big Data. Hadoop brukes til å lagre og behandle de store dataene som er distribuert over en klynge av vareserver.
Hadoop lagrer dataene ved hjelp av Hadoop distribuerte filsystem og behandler / spørrer dem ved hjelp av Map Reduce programmeringsmodell.
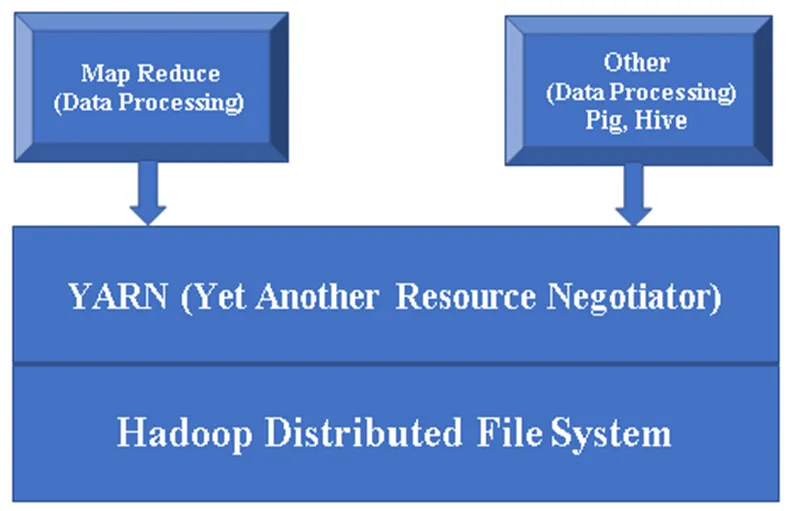
Figur 1, en grunnleggende arkitektur av en Hadoop-komponent.
Hadoops viktigste komponenter:
Hadoop Base / Common: Hadoop common vil gi deg en plattform for å installere alle komponentene.
HDFS (Hadoop Distribuerte filsystem): HDFS er en viktig del av Hadoop-rammeverket, det tar vare på alle dataene i Hadoop Cluster. Den fungerer på Master / Slave Architecture og lagrer dataene ved hjelp av replikering.
Master / slavearkitektur og replikering:
- Master Node / Name Node: Name node lagrer metadataene for hver blokk / fil som er lagret i HDFS, HDFS kan bare ha en hovednode (i tilfelle av HA vil en annen Master Node fungere som Secondary Master Node).
- Slave Node / Data Node: Datanoder inneholder faktiske datafiler i blokker. HDFS kan ha flere datanoder.
- Replikering: HDFS lagrer dataene sine ved å dele dem opp i blokker. Standard blokkstørrelse er 64 MB. På grunn av replikasjonsdata blir lagret i 3 (standardreplikasjonsfaktor, kan økes iht. Krav). Forskjellige datanoder, og det er derfor minst mulig mulighet for å miste dataene i tilfelle knutepunktfeil.
Garn (Yet Another Resource Negotiator): Det brukes i utgangspunktet for å administrere Hadoop-ressurser, og det spiller en viktig rolle i planleggingen av brukernes applikasjon.
MR (Map Reduce): Dette er den grunnleggende programmeringsmodellen til Hadoop. Den brukes til å behandle / spørre dataene innenfor Hadoop rammeverk.
Hive:
Hive er et program som kjører over Hadoop-rammeverket og gir SQL-lignende grensesnitt for behandling / spørring av dataene. Hive er designet og utviklet av Facebook før den blir en del av Apache-Hadoop-prosjektet.
Hive kjører spørringen ved å bruke HQL (Hive-spørrespråk). Hive har samme struktur som RDBMS, og nesten samme kommandoer kan brukes i Hive.
Hive kan lagre dataene i eksterne tabeller, så det er ikke obligatorisk å bruke HDFS, den støtter også filformater som ORC, Avro-filer, Sekvensfil og tekstfiler etc.
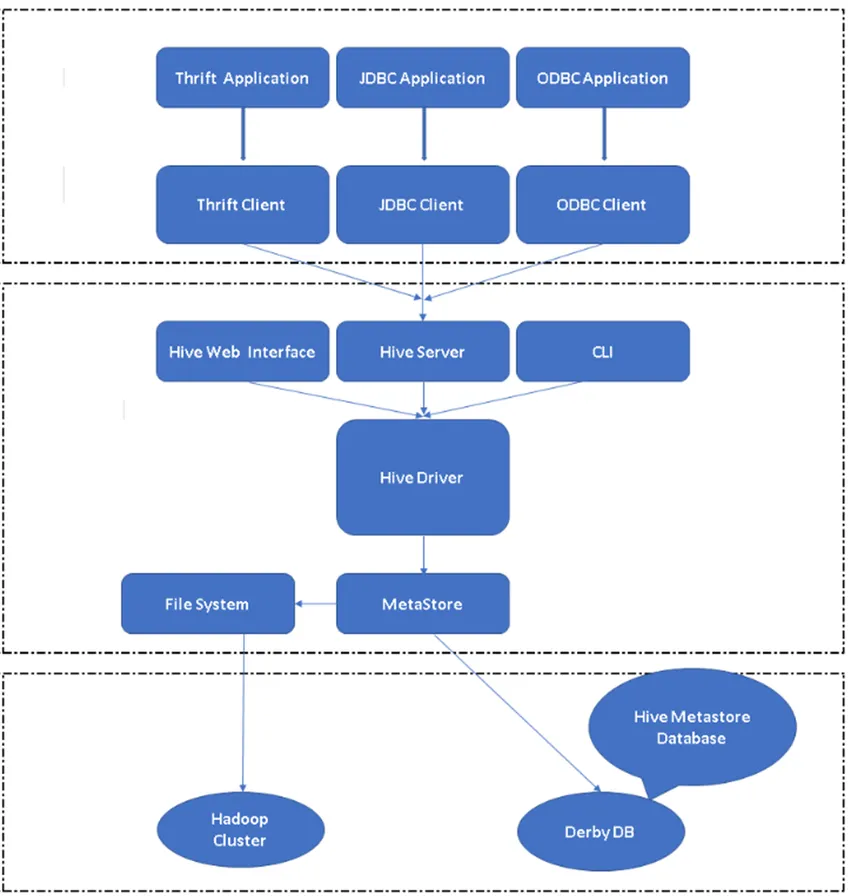
Figur 2, Hive's Architecture & It's hovedkomponenter.
Hives viktigste komponent:
Hive-klienter: Ikke bare SQL, Hive støtter også programmeringsspråk som Java, C, Python ved bruk av forskjellige drivere som ODBC, JDBC og Thrift. Man kan skrive en hvilken som helst bikubeklientapplikasjon på andre språk og kan kjøre i Hive ved hjelp av disse klientene.
Hive-tjenester: Under Hive-tjenester foregår utførelse av kommandoer og spørsmål. Hive web-grensesnitt har fem underkomponenter.
- CLI: Standard kommandolinjegrensesnitt levert av Hive for utføring av Hive-spørsmål / kommandoer.
- Hive Web-grensesnitt: Det er et enkelt grafisk brukergrensesnitt. Det er et alternativ til Hive-kommandolinjen og brukes til å kjøre spørsmål og kommandoer i Hive-applikasjonen.
- Hive Server: Det kalles også Apache Thrift. Det er ansvarlig å ta kommandoer fra forskjellige forskjellige kommandolinjegrensesnitt og sende inn alle kommandoene / spørringene til Hive, også henter det endelige resultatet.
- Apache Hive Driver: Det er ansvarlig for å ta inngangene fra CLI-, web-UI-, ODBC-, JDBC- eller Thrift-grensesnittene av en klient og sende informasjonen til metastore der all filinformasjonen er lagret.
- Metastore: Metastore er et depot for å lagre all Hive-metadatainformasjon. Hives metadata lagrer informasjonen som strukturen av tabeller, partisjoner og kolonnetype osv …
Hive Storage: Det er stedet der den faktiske oppgaven blir utført. Alle spørsmålene som kjøres fra Hive utførte handlingen i Hive-lagring.
Sammenligning mellom hodet og hodet mellom Hadoop vs Hive (Infographics)
Nedenfor er topp 8-forskjellen mellom Hadoop vs Hive
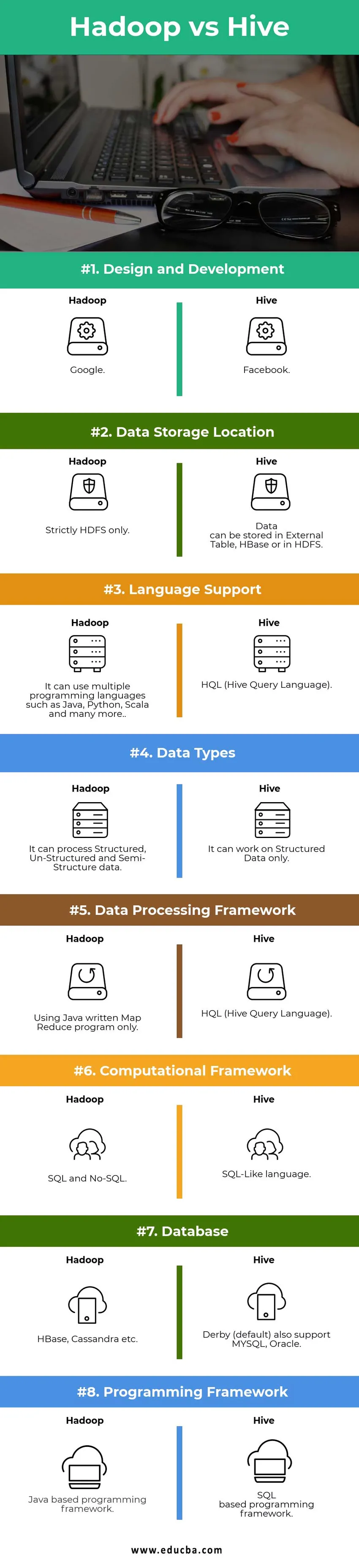
Viktige forskjeller mellom Hadoop vs Hive:
Nedenfor er listen over punkter, som beskriver de viktigste forskjellene mellom Hadoop og Hive:
1) Hadoop er et rammeverk for å behandle / spørre Big data mens Hive er et SQL-basert verktøy som bygger over Hadoop for å behandle dataene.
2) Hive prosess / spørring alle data ved hjelp av HQL (Hive Query Language) det er SQL-lignende språk mens Hadoop kan forstå Map Reduce bare.
3) Map Reduce er en integrert del av Hadoop. Hives spørsmål blir først konvertert til Map Reduce enn behandlet av Hadoop for å spørre dataene.
4) Hive fungerer på SQL Like-spørring mens Hadoop forstår det ved å bruke Java-basert Map Reduce.
5) I Hive kan tidligere brukte tradisjonelle “Relational Database's” -kommandoer også brukes til å spørre om big data mens du er i Hadoop, og må skrive komplekse Map Reduce-programmer ved hjelp av Java som ikke ligner på tradisjon Java.
6) Hive kan bare behandle / spørre om de strukturerte dataene mens Hadoop er ment for all type data enten det er strukturert, ustrukturert eller semistrukturert.
7) Ved å bruke Hive kan man behandle / spørre dataene uten komplisert programmering mens i Simple Hadoop-økosystemet, trenger å skrive et komplekst Java-program for de samme dataene.
8) Hadoop-rammeverk på den ene siden trenger 100-talls linje for å forberede Java-basert MR-program, en annen side Hadoop med Hive kan spørre om de samme dataene ved å bruke 8 til 10 linjer med HQL.
9) I Hive er det veldig vanskelig å sette inn utdataene fra en spørring som inndata fra en annen, mens den samme spørringen enkelt kan gjøres ved bruk av Hadoop med MR.
10) Det er ikke obligatorisk å ha Metastore i Hadoop-klyngen, mens Hadoop lagrer alle metadataene sine inne i HDFS (Hadoop Distribuerte filsystem).
Hadoop vs Hive sammenligningstabell
| Sammenligningspoeng | Hive | Hadoop |
|
Design og utvikling | ||
| Datalagringsplassering |
Data kan lagres i eksternt Tabell, HBase eller i HDFS. | Strengt tatt bare HDFS. |
| Språkstøtte | HQL (Hive Query Language) |
Den kan bruke flere programmeringsspråk som Java, Python, Scala og mange flere. |
| Datatyper | Den kan bare fungere på strukturerte data. |
Det kan behandle strukturerte, ustrukturerte og semistrukturerte data. |
| Rammeverk for databehandling |
HQL (Hive Query Language) | Bruk bare av Java skrevet Map Reduce-program. |
|
Beregningsramme | SQL-lignende språk. | SQL og No-SQL. |
| database |
Derby (standard) støtter også MYSQL, Oracle … | HBase, Cassandra osv…. |
| Programmeringsrammeverk |
SQL-basert programmeringsramme. | Java-basert programmeringsramme. |
Konklusjon - Hadoop vs Hive
Hadoop og Hive er begge brukt til å behandle Big data. Hadoop er et rammeverk som gir plattformer for andre applikasjoner for å spørre / behandle Big Data mens Hive bare er en SQL-basert applikasjon som behandler dataene ved hjelp av HQL (Hive Query Language)
Hadoop kan brukes uten Hive for å behandle big data, mens det ikke er lett å bruke Hive uten Hadoop.
Som en konklusjon kan vi ikke sammenligne Hadoop og Hive på noen måte og på noe aspekt. Både Hadoop og Hive er helt forskjellige. Å kjøre begge teknologiene sammen kan gjøre Big Data-spørringsprosessen mye enklere og behagelig for Big Data-brukere.
Anbefalte artikler:
Dette har vært en guide til Hadoop vs Hive, deres betydning, sammenligning mellom hodet og hodet, nøkkelforskjeller, sammenligningstabell og konklusjon. Du kan også se på følgende artikler for å lære mer -
- Hadoop vs Apache Spark - Interessante ting du trenger å vite
- HADOOP vs RDBMS | Vet de 12 nyttige forskjellene
- Hvordan Big Data endrer ansiktet til helsevesenet
- Topp 12 sammenligning av Apache Hive vs Apache HBase (Infographics)
- Fantastisk guide på Hadoop vs Spark