
Introduksjon til dataanalyseteknikker
I det 21. århundre er dataanalyse et av de mest brukte ordene i hvert domene. La oss i dag se hva betyr alle med dataanalyse og noen viktige teknikker i dataanalyse. Dataanalyse er prosessen med å inspisere, rense, transformere og modellere data med en intensjon om å oppdage nyttig informasjon som kan gjøre beslutningen bedre. I 2019 sa økonomen, "Verdens mest verdifulle eiendel er ikke lenger olje, men DATA". Dataanalyse er nært knyttet til datavisualisering. Basert på datamengden som næringene genererer hvert minutt, og basert på deres behov er det en rekke teknikker som kom til. La oss se hva de er i neste avsnitt. I dette emnet skal vi lære om typer dataanalyseteknikker.
Viktige typer dataanalyseteknikker
Dataanalyseteknikker er stort sett klassifisert i to typer de er
- Metoder basert på matematiske og statistiske tilnærminger
- Metoder basert på kunstig intelligens og maskinlæring
Matematiske og statistiske tilnærminger
1. Beskrivende analyse: Beskrivende analyse er et viktig første skritt for å utføre statistisk analyse. Det gir oss en ide om distribusjon av data, hjelper til med å oppdage outliers, og gjør det mulig for oss å identifisere assosiasjoner mellom variabler, og dermed forberede dataene til å utføre ytterligere statistisk analyse. Beskrivende analyse av et enormt datasett kan gjøres enkelt ved å dele det inn i to kategorier, de er beskrivende analyser for hver individuelle variabel og beskrivende analyse for kombinasjoner av variabler.
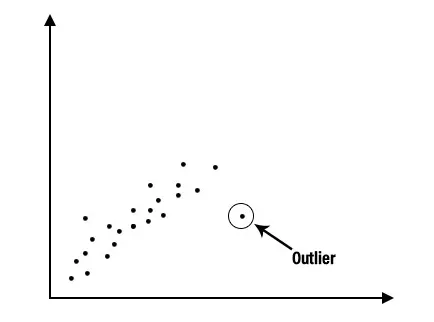
2. Regresjonsanalyse: Regresjonsanalyse er en av de dominerende teknikker for dataanalyse som brukes i bransjen akkurat nå. I denne typen teknikker kan vi se forholdet mellom to eller flere variabler av interesse og i kjernen, de studerer alle påvirkningen av en eller flere uavhengige variabler på den avhengige variabelen. For å se om det er noe forhold mellom variablene eller ikke, må vi først plotte dataene på et diagram, og det vil være tydelig om det er noen relasjon. Vurder for eksempel grafen som er tegnet nedenfor for å ha en klar forståelse.
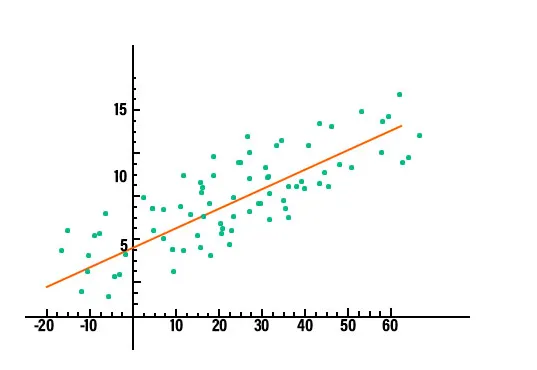
I data mining brukes denne teknikken til å forutsi verdiene til en variabel, i det aktuelle datasettet. Det er forskjellige typer regresjonsmodeller i bruk. Noen få av dem er lineær regresjon, logistisk regresjon og multippel regresjon.
3. Spredningsanalyse: Spredning er i hvilken grad en distribusjon blir strukket eller klemt. I den matematiske tilnærmingen kan spredningen defineres på to måter, fundamentalt forskjellen mellom verdier seg imellom og for det andre forskjellen mellom gjennomsnittsverdien. Hvis forskjellen mellom verdien og gjennomsnittet er veldig lav, kan vi si at spredningen er mindre i dette tilfellet. Og noen av de vanlige målene for spredning er varians, standardavvik og interkvartil rekkevidde.
4. Faktoranalyse: Faktoranalyse er en slags dataanalyseteknikk, som hjelper med å finne den underliggende strukturen i et sett med variabler. Det hjelper med å finne uavhengige variabler i datasettet som beskriver mønstre og modeller av forhold. Det er det første trinnet mot prosedyrer for klynging og klassifisering. Faktoranalyse er også relatert til Principal Component Analyse (PCA), men begge er ikke identiske, kan vi kalle PCA som den mer grunnleggende versjonen av utforskende faktoranalyse
5. Time Series: Time series analyse er en dataanalyseteknikk som omhandler tidsseriedata eller trendanalyse. La oss nå forstå hva som er tidsseriedata? Tidsseriedata er data i en serie med bestemte tidsintervaller eller perioder. Ser vi vitenskapelig, blir de fleste målingene utført over tid.
Metoder basert på maskinlæring og kunstig intelligens
1. Beslutningstrær: Beslutningstresanalyse er en grafisk fremstilling, lik en trelignende struktur der problemene i beslutningsprosessen kan sees i form av et flytskjema, hver med grener for alternative svar. Beslutningstrær er en ovenfra og ned tilnærmingstype, med den første beslutningsnoden øverst, basert på svaret på første beslutningsnode, vil den bli delt inn i grener, og den vil fortsette til treet kommer til en endelig beslutning. Grenene som ikke deler seg mer er kjent som blader.
2. Nevrale nettverk: Nevrale nettverk er et sett med algoritmer, som er designet for å etterligne den menneskelige hjernen. Det er også kjent som “Network of Artificial neurons”. Bruken av nevralt nettverk i data mining er veldig bredt. De har en god aksept for evne til støyende data og resultater med høy nøyaktighet. Basert på nødvendigheten brukes mange typer nevrale nettverk for tiden, få av dem er tilbakevendende nevrale nettverk og innviklede nevrale nettverk. Konvensjonelle nevrale nettverk brukes mest i bildebehandling, naturlig språkbehandling og anbefalingssystemer. Gjentagende nevrale nettverk brukes hovedsakelig til håndskrift og talegjenkjenning.
3. Evolusjonære algoritmer: Evolusjonære algoritmer bruker mekanismene inspirert av rekombinasjon og seleksjon. Disse typer algoritmer er uavhengige av domenet, og de har muligheten til å utforske store datasett, oppdage mønstre og løsninger. De er følsomme for støy sammenlignet med andre datateknikker.
4. Uklar logikk: Det er en tilnærming i databehandling basert på "Grad of sannhet" snarere enn den vanlige "Boolsk logikk" (sannhet / usann eller 0/1). Som diskutert ovenfor i beslutningstrær ved beslutningsnode har vi enten ja eller nei som svar, hva om vi har en situasjon der vi ikke kan bestemme absolutt ja eller absolutt nei? I disse tilfellene spiller uklar logikk en viktig rolle. Det er en mangfoldig verdsatt logikk der sannhetsverdien kan være mellom helt sann og helt falsk, det vil si at den kan ta hvilken som helst reell verdi mellom 0 og 1. Uklar logikk er anvendbar når det er en betydelig mengde støy i verdiene.
Konklusjon
Det tøffe spørsmålet som alle selskaper eller selskaper står overfor, er hvilken type dataanalyseteknikk som er best for dem? Vi kan ikke definere noen teknikk som den beste i stedet for hva vi kan gjøre er å prøve flere teknikker og se hvilken som passer best for datasettet vårt og bruke det. Ovennevnte teknikker er noen av de viktige teknikkene som i dag brukes i bransjen.
Anbefalte artikler
Dette er en guide til Typer av dataanalyseteknikker Her diskuterer vi typer av dataanalyseteknikker som for tiden brukes i bransjen. Du kan også se på følgende artikler for å lære mer -
- Data Science Tools
- Data Science-plattformen
- Data Science Karriere
- Big Data Technologies
- Clustering in Machine Learning
- Fuzzy Logic System | Når skal du bruke, arkitektur
- Komplett guide til implementering av nevrale nettverk
- Hva er dataanalyse?
- Lag beslutnings tre med fordeler
- Veiledning for forskjellige typer dataanalyse