

Introduksjon til Python Pandas DataFrame
Flere utvidelser for Python-biblioteket, Pandaer, finner du online. Et slikt er Paneldata (pan) Data (das). Dette ordet, * Panel *, antyder subtilt en 2-dimensjonal datastruktur som finnes i dette biblioteket, og gir brukerne en enorm styrke. Selve strukturen kalles en DataFrame.
Det er egentlig en matrise av rader og kolonner, som inneholder hele datasettet, med veldig forseggjorte alternativer for å indeksere det samme. DataFrame (DF), kan tenkes billedlig sett veldig likt et excelark. Men det som gjør det kraftig, er det enkelt med analyse- og transformasjonsoperasjoner som kan utføres på dataene som er lagret i en DataFrame.
Hva er egentlig en Python Pandas DataFrame?
Pydata-side kan henvises for noe av en offisiell definisjon.
Hvis den forstås riktig, omtaler den DataFrame som en søylestruktur, som er i stand til å lagre ethvert pythonobjekt (inkludert et DataFrame i seg selv) som en celleverdi. (En celle indekseres ved hjelp av en unik kombinasjon av rad og kolonne)
DataFrames består av tre essensielle komponenter: data, rader og kolonner.
- Data: Det refererer til de faktiske objektene / enhetene som er lagret i en celle i DataFrame og verdiene som er representert av disse enhetene. Et objekt er av en gyldig python-datatype, enten det er innebygd eller brukerdefinert.
- Rader: Referanser som brukes til å identifisere (eller indeksere) et bestemt sett med observasjoner fra de komplette dataene som er lagret i en DataFrame, kalles Rows. Bare for å gjøre det klart, representerer det indeksene som er brukt og ikke bare dataene i en bestemt observasjon.
- Kolonner: Referanser som brukes til å identifisere (eller indeksere) et sett attributter for alle observasjonene i en DataFrame. Som for rader, refererer disse til kolonneindeksen (eller kolonneoverskriftene) i stedet for bare dataene i kolonnen.
La oss prøve noen måter å skape disse forferdelig kraftige strukturer uten videre.
Trinn for å opprette Python Pandas DataFrames
En Python Pandas DataFrame kan opprettes ved hjelp av følgende kodeimplementering,
1. Importer pandaer
For å lage DataFrames, må pandabiblioteket importeres (ingen overraskelse her). Vi importerer den med et alias pd for å referere til objekter under modulen på en enkel måte.
Kode:
import pandas as pd
2. Opprette det første DataFrame-objektet
Når biblioteket er importert, er alle metodene, funksjonene og konstruktørene tilgjengelige i arbeidsområdet ditt. Så la oss prøve å opprette en vanilje DataFrame.
Kode:
import pandas as pd
df = pd.DataFrame()
print(df)
Produksjon:
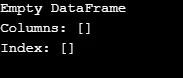
Som vist i utgangen returnerer konstruktøren en tom DataFrame.
La oss nå fokusere på å lage DataFrames fra data som er lagret i noen av de sannsynlige representasjonene.
- DataFrame fra A Dictionary: La oss si at vi har en ordbok som lagrer en liste over selskaper i Software Domain og antall år de har vært aktive.
Kode:
import pandas as pd
df = pd.DataFrame(
('Company':('Google', 'Amazon', 'Infosys', 'Directi'),
'Age':('21', '23', '38', '22') ))
print (df)
La oss se representasjonen av det returnerte DataFrame-objektet ved å skrive det ut på konsollen.
Produksjon:

Som det kan ses, blir hver nøkkel i ordboken behandlet som en kolonne i DataFrame, og radindeksene genereres automatisk fra 0. Ganske enkelt va!
La oss si at du ønsket å gi den en tilpasset indeks i stedet for 0, 1, .. 4. Du trenger bare å sende den ønskede listen som en parameter til konstruktøren, og pandaer vil gjøre det nødvendig.
Kode:
df = pd.DataFrame(
('Company':('Google', 'Amazon', 'Yahoo', 'Infosys', 'Directi'),
'Age':('21', '23', '24', '38', '22') ),
index=('Alpha', 'Beta', 'Gamma', 'Delta'))
print(df)
Produksjon:
Bedriftens alder
Alpha Google 21
Beta Amazon 23
Gamma Infosys 38
Delta Directi 22
Nå kan du stille radindekser til ønsket verdi.
- DataFrame fra en CSV-fil: La oss lage en CSV-fil som inneholder de samme dataene som for vår ordbok. La oss kalle filen CompanyAge.csv
Google, 21
Amazon, 23
Infosys, 38
Directi, 22
Filen kan lastes inn i et dataramme (forutsatt at den er til stede i gjeldende arbeidskatalog) som følger.
Kode:
csv_df = pd.read_csv(
'CompanyAge.csv', names=('Company', 'Age'), header=None)
print(csv_df)
Produksjon:
Bedriftens alder
0 Google 21
1 Amazon 23
2 informasjon 38
3 Directi 22
Innstilling av parameternavn , omgåelse av en liste med verdier, tilordner dem som kolonneoverskrifter i samme rekkefølge som de er til stede i listen. Tilsvarende kan rekkeindekser settes ved å føre en liste til indeksparameteren, som vist i forrige seksjon. Overskriften = Ingen indikerer manglende kolonneoverskrifter i datafilen.
La oss si at kolonnenavnene var en del av datafilen. Da setter inn overskrift = Falske vil gjøre den nødvendige jobben.
3. CompanyAgeWithHeader.csv
Selskap, alder
Google, 21
Amazon, 23
Infosys, 38
Directi, 22
Koden endres til
csv_df = pd.read_csv(
'CompanyAgeWithHeader.csv', header=False)
print(csv_df)
Produksjon:
Bedriftens alder
0 Google 21
1 Amazon 23
2 informasjon 38
3 Directi 22
- DataFrame fra en Excel-fil: Ofte blir data delt i excel-filer, da de forblir det mest populære verktøyet som brukes av vanlige folk til Adhoc-sporing. Dermed bør det ikke ignoreres av diskusjonen vår.
La oss anta at dataene, de samme som i CompanyAgeWithHeader.csv, nå er lagret i CompanyAgeWithHeader.xlsx, i et ark med navnet Company Age. Den samme DataFrame som ovenfor vil bli opprettet med følgende kode.
Kode:
excel_df= pd.read_excel('CompanyAgeWithHeader.xlsx', sheet_name='CompanyAge')
print(excel_df)
Produksjon:
Bedriftens alder
0 Google 21
1 Amazon 23
2 informasjon 38
3 Directi 22
Som du kan se, kan den samme DataFrame opprettes ved å gi filnavnet og arknavnet.
Videre lesing og neste trinn
Metodene som vises utgjør en veldig liten undergruppe sammenlignet med alle de forskjellige måtene DataFrames kan opprettes. Disse ble opprettet med den hensikt å komme i gang. Du bør absolutt utforske referansene som er oppført og prøve å utforske andre måter, inkludert å koble til en database for å lese data fra direkte inn i en DataFrame.
Konklusjon
Pandas DataFrame har vist seg å være en spillutveksler i verden av Data Science og Data Analytics, så vel som praktisk for ad-hoc kortsiktige prosjekter. Den kommer med en hær av verktøy som er i stand til å skive og terning av datasettet med ekstrem letthet. Forhåpentligvis vil dette tjene som et springbrett i reisen din fremover.
Anbefalte artikler
Dette er en guide til Python-Pandas DataFrame. Her diskuterer vi trinnene for å lage python-pandas dataframe sammen med kodekonvertering. Du kan også se på følgende artikler for å lære mer -
- Topp 15 funksjoner i Python
- Ulike typer Python-sett
- Topp 4 typer variabler i Python
- Topp 6 redaktører av Python
- Arrays i datastruktur