

Deep Learning Interview Spørsmål og svar
I dag er Deep Learning blitt sett på som en av de raskest voksende teknologiene med en enorm evne til å utvikle en applikasjon som har blitt sett på som tøff for en tid tilbake. Talegjenkjenning, bildegjenkjenning, finne mønstre i et datasett, objektklassifisering i fotografier, generering av karaktertekst, selvkjørende biler og mange flere er bare noen få eksempler der Deep Learning har vist sin betydning.
Så du har endelig funnet drømmejobben din i Deep Learning, men lurer på hvordan du kan knekke Deep Learning-intervjuet og hva som kan være de sannsynlige Deep Learning Interview-spørsmålene. Hvert intervju er forskjellig, og omfanget av en jobb er også annerledes. Med dette i bakhodet har vi designet de vanligste spørsmålene og svarene om Deep Learning-intervju for å hjelpe deg med å få suksess i intervjuet.
Nedenfor er noen spørsmål om Deep Learning Interview som ofte stilles i Interview, og som også kan hjelpe deg med å teste nivåene dine:
Del 1 - Spørsmål om dybdeintervju (grunnleggende)
Denne første delen dekker grunnleggende spørsmål om svar på Deep Learning-intervju
1. Hva er dyp læring?
Svar:
Området med maskinlæring som fokuserer på dype kunstige nevrale nettverk som er løst inspirert av hjerner. Alexey Grigorevich Ivakhnenko publiserte den første generalen om å jobbe Deep Learning-nettverket. I dag har applikasjonen sin innen forskjellige felt som datasyre, talegjenkjenning, naturlig språkbehandling.
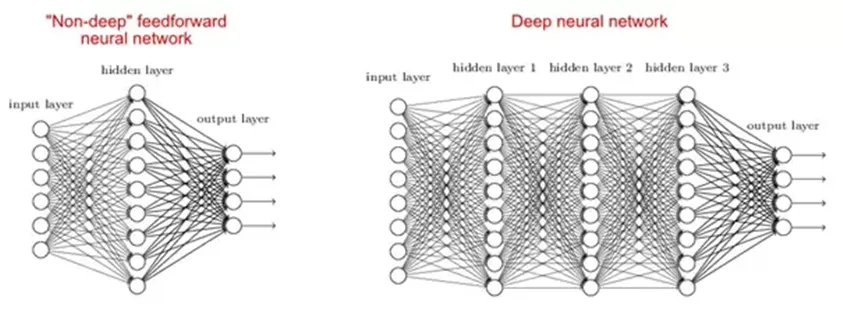
2. Hvorfor er dype nettverk bedre enn grunne nettverk?
Svar:
Det er studier som sier at både grunne og dype nettverk kan passe til enhver funksjon, men ettersom dype nettverk har flere skjulte lag ofte av forskjellige typer, så de er i stand til å bygge eller trekke ut bedre funksjoner enn grunne modeller med færre parametere.
3. Hva er kostnadsfunksjonen?
Svar:
En kostnadsfunksjon er et mål på nøyaktigheten til det nevrale nettverket med hensyn til den gitte treningsprøven og forventet effekt. Det er en enkelt verdi, ikke-vektor, ettersom den gir ytelsen til nevrale nettverk som helhet. Det kan beregnes som nedenfor gjennomsnittlig kvadratfeilfunksjon: -
MSE = 1nΣi = 0 n (Y i-Yi) 2
Hvor Y og ønsket verdi Y er det vi ønsker å minimere.
La oss gå til de neste spørsmålene om Deep Learning Interview.
4. Hva er gradient nedstigning?
Svar:
Gradient nedstigning er i utgangspunktet en optimaliseringsalgoritme, som brukes til å lære verdien av parametere som minimerer kostnadsfunksjonen. Det er en iterativ algoritme som beveger seg i retning av bratteste nedstigning som definert av det negative av gradienten. Vi beregner gradient nedstigningen av kostnadsfunksjonen for en gitt parameter og oppdaterer parameteren med formelen nedenfor: -
Θ: = Θ-αd∂ΘJ (Θ)
Hvor Θ - er parametervektoren, er α - læringsfrekvens, J (Θ) - en kostnadsfunksjon.
5. Hva er bakpropagering?
Svar:
Backpropagation er en treningsalgoritme som brukes for et flerlags nevralt nettverk. I denne metoden flytter vi feilen fra en ende av nettverket til alle vekter inne i nettverket og dermed tillater effektiv beregning av gradienten. Det kan deles inn i flere trinn som følger:
Fremoverformidling av treningsdata for å generere output.
Da kan bruk av målverdi og utgangsverdi feilderivat beregnes med hensyn til utgangsaktivering.
Da backpagneres vi for beregning av deriverte av feilen med hensyn til utgangsaktivering på forrige og fortsetter dette for alle skjulte lag.
Bruker tidligere kalkulerte derivater for output og alle skjulte lag beregner vi feilderivater med hensyn til vekter.
Og så oppdaterer vi vektene.
6. Forklar følgende tre varianter av gradient nedstigning: batch, stokastisk og mini-batch?
Svar:
Stokastisk gradientnedstigning : Her bruker vi bare et enkelt treningseksempel for beregning av gradient- og oppdateringsparametere.
Batch Gradient Descent : Her beregner vi gradienten for hele datasettet og utfører oppdateringen ved hver iterasjon.
Mini-batch Gradient Descent : Det er en av de mest populære optimaliseringsalgoritmene. Det er en variant av Stochastic Gradient Descent, og her i stedet for et enkelt treningseksempel, brukes mini-batch av prøver.
Del 2 - Deep Learning Interview Questions (Advanced)
La oss nå se på de avanserte spørsmålene om Deep Learning Interview.
7. Hva er fordelene med mini-batch gradient nedstigning?
Svar:
Nedenfor er fordelene med mini-batch gradient nedstigning
• Dette er mer effektivt sammenlignet med stokastisk gradientavstigning.
• Generaliseringen ved å finne den flate minimaen.
• Mini-partier gir hjelp til å tilnærme gradienten til hele treningssettet som hjelper oss med å unngå lokale minima.
8. Hva er dataanormalisering og hvorfor trenger vi det?
Svar:
Datanormalisering brukes under tilbakepropagering. Hovedmotivet bak dataanormalisering er å redusere eller eliminere dataredundans. Her omskalerer vi verdier for å passe inn i et spesifikt område for å oppnå bedre konvergens.
La oss gå til de neste spørsmålene om Deep Learning Interview.
9. Hva er vektinitialisering i nevrale nettverk?
Svar:
Vektinitialisering er et av de veldig viktige trinnene. En dårlig vektinitialisering kan forhindre at et nettverk lærer, men god vektinitiering hjelper deg med å gi en raskere konvergens og en bedre totalfeil. Forskjeller kan generelt initialiseres til null. Regelen for å stille vektene er å være nær null uten å være for liten.
10. Hva er en automatisk koder?
Svar:
En autoencoder er en autonom maskinlæringsalgoritme som bruker backpropagation-prinsippet, der målverdiene er satt til å være lik inngangene som gis. Internt har den et skjult lag som beskriver en kode som brukes til å representere inngangen.
Noen viktige fakta om autokoderen er som følger:
• Det er en ikke-overvåket ML-algoritme som ligner på prinsippkomponentanalyse
• Den minimerer den samme objektive funksjonen som Principal Component Analysis
• Det er et nevralt nettverk
• Målet for det nevrale nettverket er input
11. Er det OK å koble fra en Layer 4-utgang tilbake til en Layer 2-inngang?
Svar:
Ja, dette kan gjøres med tanke på at lag 4-utgangen er fra forrige tidstrinn som i RNN. Vi må også anta at den forrige inngangsgruppen noen ganger er korrelert med gjeldende batch.
La oss gå til de neste spørsmålene om Deep Learning Interview.
12. Hva er Boltzmann-maskinen?
Svar:
Boltzmann Machine brukes til å optimalisere løsningen på et problem. Arbeidet med Boltzmann-maskinen er i utgangspunktet å optimalisere vektene og mengden for det gitte problemet.
Noen viktige punkter om Boltzmann Machine -
• Den bruker en tilbakevendende struktur.
• Den består av stokastiske nevroner, som består av en av de to mulige tilstandene, enten 1 eller 0.
• Nevronene i dette er enten i en adaptiv (fri tilstand) eller klemt (frossen tilstand).
• Hvis vi bruker simulert annealing på diskret Hopfield-nettverk, ville det blitt Boltzmann Machine.
13. Hva er aktiviseringsfunksjonens rolle?
Svar:
Aktiveringsfunksjonen brukes til å introdusere ikke-linearitet i det nevrale nettverket og hjelper den å lære mer komplekse funksjoner. Uten hvilken ville det nevrale nettverket bare være i stand til å lære lineær funksjon som er en lineær kombinasjon av dens inndata.
Anbefalte artikler
Dette har vært en guide til Liste over spørsmål og svar på Deep Learning-intervjuer, slik at kandidaten lett kan slå sammen disse Deep Learning-intervjuspørsmålene. Du kan også se på følgende artikler for å lære mer
- Lær de 10 mest nyttige HBase-intervjuspørsmål
- Nyttige spørsmål om maskinlæring av intervju og svar
- Topp 5 mest verdifulle spørsmål om datavitenskap
- Viktige spørsmål om Ruby-intervju og svar