
Introduksjon til bagging og boosting
Bagging and Boosting er de to populære ensemblemetodene. Så før vi forstår Bagging and Boosting, la oss ha en ide om hva som er ensemble Learning. Det er teknikken å bruke flere læringsalgoritmer for å trene modeller med samme datasett for å få en prediksjon i maskinlæring. Etter å ha fått prediksjonen fra hver modell vil vi bruke modellgjennomsnittsteknikker som vektet gjennomsnitt, varians eller maks stemme for å få den endelige prediksjonen. Denne metoden tar sikte på å oppnå bedre spådommer enn den enkelte modell. Dette resulterer i bedre nøyaktighet og unngår overmontering og reduserer skjevhet og samvarians. To populære ensemblemetoder er:
- Bagging (Bootstrap Aggregating)
- Styrking
bagging:
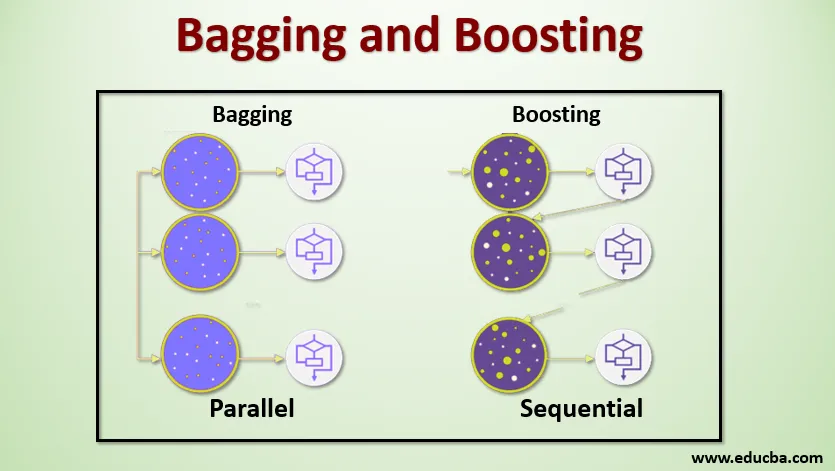
Bagging, også kjent som Bootstrap Aggregating, brukes til å forbedre nøyaktigheten og gjør modellen mer generalisert ved å redusere variansen, dvs. ved å unngå overmontering. I dette tar vi flere undergrupper av treningsdatasettet. For hvert undersett tar vi en modell med de samme læringsalgoritmene som Decision tree, Logistic regression, etc. for å forutsi output for det samme settet med testdata. Når vi har en prediksjon fra hver modell, bruker vi en modellgjennomsnittsteknikk for å få den endelige prediksjonsutgangen. En av de berømte teknikkene som brukes i Bagging er Random Forest . I den tilfeldige skogen bruker vi flere beslutnings-trær.
Boosting :
Boosting brukes først og fremst for å redusere skjevhet og varians i en veiledet læringsteknikk. Den refererer til familien til en algoritme som konverterer svake elever (basiselev) til sterke elever. Den svake eleven er klassifisatorene som bare er korrekte i liten grad med den faktiske klassifiseringen, mens de sterke elevene er klassifisererne som er godt korrelert med den faktiske klassifiseringen. Få kjente teknikker for Boosting er AdaBoost, GRADIENT BOOSTING, XgBOOST (Extreme Gradient Boosting). Så nå vet vi hva bagging og boosting er, og hva er deres roller i maskinlæring.
Working of Bagging and Boosting
La oss nå forstå hvordan bagging og boosting fungerer:
bagging
For å forstå hvordan Bagging fungerer, antar vi at vi har et N antall modeller og et datasett D. Hvor m er antall data og n er antall funksjoner i hver data. Og vi skal visstnok gjøre binær klassifisering. Først deler vi datasettet. Foreløpig vil vi dele dette datasettet bare i trenings- og testsett. La oss kalle treningsdatasettet som hvor det totale antallet treningseksempler er.
Ta et utvalg av rekorder fra treningssettet og bruk det til å trene den første modellen si m1. For den neste modellen skal du mampe treningssettet på nytt og ta et nytt utvalg fra treningssettet. Vi vil gjøre det samme for N antall modeller. Siden vi sampler treningsdatasettet på nytt og tar prøvene fra det uten å fjerne noe fra datasettet, kan det være mulig at vi har to eller flere treningsdatarekorder som er felles i flere prøver. Denne teknikken for å resample treningsdatasettet og gi prøven til modellen blir betegnet som Row Sampling with Replacement. Anta at vi har trent hver modell, og nå ønsker vi å se prediksjonen på testdata. Siden vi jobber med binær klassifisering kan output være enten 0 eller 1. Testdatasettet sendes til hver modell, og vi får en prediksjon fra hver modell. La oss si fra N-modeller mer enn N / 2-modeller spådde at den skulle være 1, og derfor kan vi si at den forutsagte utdata for testdataene er 1 ved å bruke modellgjennomsnittsteknikken som maksimal stemme.
Styrking
Når vi styrker, tar vi poster fra datasettet og gir det til baseleverandeler i rekkefølge, her kan baselever være en hvilken som helst modell. Anta at vi har flere antall poster i datasettet. Så passerer vi noen få poster for å basere lærer BL1 og trene den. Når BL1 er blitt opplært, passerer vi alle postene fra datasettet og ser hvordan Base-eleven fungerer. For alle postene som er klassifisert feil av grunnleggeren, tar vi dem bare og gir det til andre grunnleggende elever si BL2, og samtidig passerer vi de uriktige postene klassifisert av BL2 for å trene BL3. Dette vil fortsette med mindre og før vi spesifiserer et bestemt antall baserte elevmodeller vi trenger. Til slutt kombinerer vi utdataene fra disse baseleverne og skaper en sterk elev, som et resultat blir prediksjonskraften til modellen forbedret. Ok. Så nå vet vi hvordan Bagging and Boosting fungerer.
Fordeler og ulemper med bagging og boosting
Nedenfor er de viktigste fordeler og ulemper.
Fordeler med bagging
- Den største fordelen med bagging er at flere svake elever kan jobbe bedre enn en enkelt sterk elev.
- Det gir stabilitet og øker nøyaktigheten til maskinlæringsalgoritmen som brukes i statistisk klassifisering og regresjon.
- Det hjelper med å redusere varians, dvs. at det unngår overmasse.
Ulemper ved bagging
- Det kan føre til høy skjevhet hvis den ikke er riktig modellert og dermed kan føre til underinnredning.
- Siden vi må bruke flere modeller, blir det beregningsdyktig og er kanskje ikke egnet i forskjellige brukssaker.
Fordeler med boosting
- Det er en av de mest vellykkede teknikkene i å løse toklassers klassifiseringsproblemer.
- Den er flink til å håndtere de manglende dataene.
Ulemper med Boosting
- Boosting er vanskelig å implementere i sanntid på grunn av den økte kompleksiteten til algoritmen.
- Høy fleksibilitet av denne teknikken resulterer i flere parametre enn som har en direkte effekt på atferden til modellen.
Konklusjon
Den viktigste takeawayen er at Bagging and Boosting er et maskinlæringsparadigme der vi bruker flere modeller for å løse det samme problemet og få en bedre ytelse. Hvis vi kombinerer svake elever på riktig måte, kan vi få en stabil, nøyaktig og en robust modell. I denne artikkelen har jeg gitt en grunnleggende oversikt over Bagging and Boosting. I de kommende artiklene vil du bli kjent med de forskjellige teknikkene som brukes i begge deler. Til slutt vil jeg konkludere med å minne om at Bagging and Boosting er blant de mest brukte teknikkene for ensemblæring. Den virkelige kunsten å forbedre ytelsen ligger i din forståelse av når du skal bruke hvilken modell og hvordan du innstiller hyperparametrene.
Anbefalte artikler
Dette er en guide til bagging og boosting. Her diskuterer vi introduksjonen til bagging og boosting, og det fungerer sammen med fordeler og ulemper. Du kan også gå gjennom andre foreslåtte artikler for å lære mer -
- Introduksjon til ensembleteknikker
- Kategorier av maskinlæringsalgoritmer
- Gradient Boosting Algorithm with Sample Code
- Hva er den boostende algoritmen?
- Hvordan lage beslutningstre?