

Introduksjon til Data Engineer Intervju Spørsmål og svar
Datateknikk er et begrep der alle er klar over det og er ganske populære innen Big Data. Datateknikk refererer til datainfrastruktur eller dataarkitektur. Rå data generert fra forskjellige kilder, for eksempel sosiale medier, mobiltelefoner, www (internett), må transformeres, renses, profileres og samles for forretningsbehov. Disse rå dataene blir også betegnet som Dark Data. Praksisen med å designe, arkivere og implementere dataprosessystemet hjelper til med å konvertere dataene til et stykke passende informasjon eller sett med data, slik informasjon eller datasett blir betegnet som Data Engineering.
Nedenfor er listen over de beste spørsmålene og svarene om datateknikerintervju fra 2019:
Hvis du leter etter en jobb som er relatert til Data Engineer, må du forberede deg på intervjuspørsmålene til Data Engineer i 2019. Selv om alle spørsmål om datateknikerintervju er forskjellige og omfanget av en jobb også er forskjellig, kan vi hjelpe deg med de beste spørsmålene om dataingeniørintervju med svar, som vil hjelpe deg med å ta spranget og få suksess med ditt datateknikerintervju.
1. Hva er datateknikk?
Svar:
Datateknikk er et begrep som er ganske populært innen Big Data, og det refererer hovedsakelig til datainfrastruktur eller dataarkitektur.
Dataene som genereres av mange kilder som sosiale medier, mobiltelefoner, www (internett) er rå data. Det må transformeres, renses, profileres og aggregeres for forretningsbehov. Vi kan kalle disse rå dataene som Dark Data, som vi vil skinne lyset for å gjøre disse Dark Data nyttige. Praksisen med å designe, arkivere og implementere dataprosessystemet som vil bidra til å gjøre dataene konvertert til nyttig informasjon kalles Data Engineering.
2. Forklar det daglige arbeidet til en dataingeniør?
Svar:
Dataingeniør daglig jobb består av:
en. håndtere datatilsyn i organisasjonen
b. håndtering og vedlikehold av kildesystemer for data og iscenesettelsesområder
c. gjør ETL eller ELT og datatransformasjon
d. forenkle datarensing og forbedring av dataduplisering og -bygging
e. gjør ad-hoc data spørring bygging og utvinning
Se visualisering nedenfor som informerer om hvilke ting en dataingeniør jobber med: - 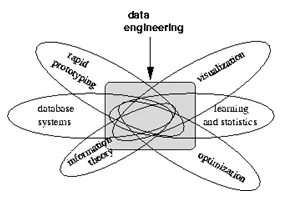
3. Har du erfaring med datamodellering?
Svar:
Man kan si at han / hun har jobbet med et prosjekt for en finans / helseforsikringsklient der de har brukt ETL-verktøy som Informatica / Talend / Pentaho etc. for å transformere og behandle data hentet fra en MySQL / RDS / SQL-database og sender ut denne informasjonen til leverandører som kan bidra til å øke inntektene. Man kan vise under høynivåarkitektur av datamodell. Den består av en primær nøkkel, enhet, attributter, forhold, begrensninger etc.
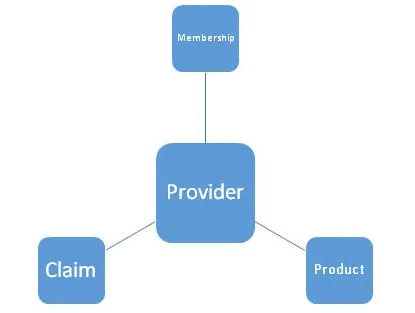
4. Hva er forskjellige typer designskjemaer i Datamodellering? Forklar med et eksempel?
Svar:
Det er to typer skjemaer i datamodellering:
en. Stjerneskema
Dette skjemaet er delt i to, ett er faktatabell og annet dimensjonstabell der alle dimensjonstabellene er koblet til en faktatabell. Faktisk tabell for fremmednøkkel refererer til primærnøkler til stede i dimensjonstabeller. Se arkitektur av stjerneskema nedenfor:
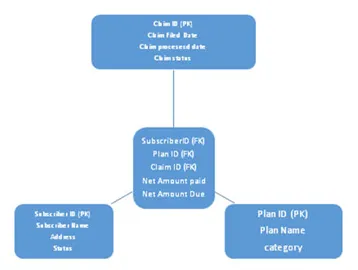
b. Snøfnuggskjema
I dette skjemaet blir normaliseringsnivået økt, her vil faktatabellen forbli den samme som for stjerneskjema, her normaliseres dimensjonstabeller. På grunn av mange lag dimensjonstabeller ser det ut som en snøfnugg, dermed navnet snøfnuggskjema. Se arkitektur nedenfor: -
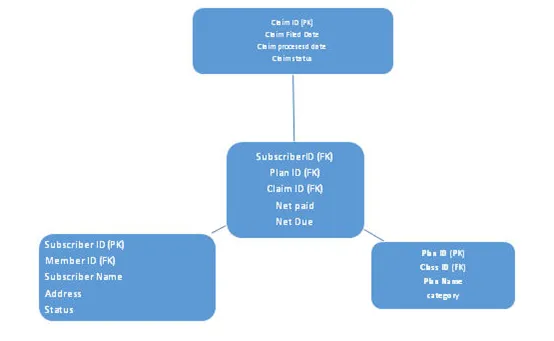
5. Hvilket ETL-verktøy du bruker og hvordan dette sammenliknes best med andre?
Svar:
Man kan si at han / hun har brukt Informatica som ETL-verktøy på grunn av mange punkter, først og fremst er at per Gartner Magic Quadrant for Data Integration Tools er Informatica posisjonert som en leder for det 10. året på rad. Det er enkelt å bruke og lære og har funksjoner for å koble til en annen rekke kildedata og datatyper, gjenbrukbare komponenter og funksjoner som gjør den mest favoritt for ETL-utviklere. Den har også en egen planlegger som er en annen fordel, der andre ETL-verktøy må bruke en ekstern planlegger for å planlegge jobbene.
6. Hvilke teknologier / programmeringsspråk skal man ha / Lær å være dataingeniør?
Svar:
Matematikk (lineær algebra og sannsynlighet)
Statistikk (sammendragsstatistikk)
Maskinlæringsteknikker
R- og SAS-språk
SQL-databaser, Hive QL
Python (mest brukt)
Bortsett fra disse, bør man ha problemløsende, analytisk og arkitektonisk kunnskap om database.
7. Hva er noen vanlige problemer som dataingeniører står overfor?
Svar:
1. Integrering i sanntid / Kontinuerlig integrasjon
2. Lagring av enorm datamengde er ett problem, informasjonen fra disse dataene er et annet problem.
3. Hvilke verktøy som kan brukes som gir best ytelse, lagring, effektivitet og resultater.
4. Har lagringsskalaen? Anta hvordan du vet det for behandling av hele datasettet hvor lang tid det vil ta?
5. Vurder prosessorene og RAM-konfigurasjonen
6. Hvordan takle feil, er feiltoleranse der eller ikke?
8. Hvordan er Data Architect forskjellig fra Data Engineer?
Svar:
Data Architect er personen som administrerer dataene, spesielt når man har å gjøre med forskjellige antall forskjellige datakilder. Man skal ha inngående kjennskap til hvordan en database fungerer, hvordan data forholder seg til forretningsproblemer og hvordan endringene vil forstyrre organisasjonens databruk og deretter vil dataarkitekt manipulere / transformere dataarkitekturen i henhold til dem.
Hovedansvaret til Data arkitekt jobber med datalagring, utvikling av dataarkitektur eller enterprise data hub / warehouse.
Mens en datatekniker hjelper til med å installere datalagerløsninger, datamodellering, utvikling og testing av databasearkitektur.
9. Beskriv et tidspunkt da du fant en ny brukssak for eksisterende database som hadde en positiv innvirkning på virksomheten?
Svar:
Mens i en epoke med Big Data, vil SQL ikke mangle funksjoner nedenfor:
en. RDBMS er skjemorientert DB, så det er bedre for strukturerte data, ikke for semistrukturerte eller ustrukturerte data.
b. Ikke i stand til å behandle uforutsigbare og ustrukturerte data.
c. Det er ikke horisontalt skalerbart, dvs. parallell utførelse og lagring er ikke mulig i SQL.
d. Det lider av ytelsesproblemer når flere brukere øker.
e. Det brukes hovedsakelig til online transaksjonsbehandling.
For å overvinne disse ulempene, kan vi bruke NoSQL DB, dvs. ikke bare SQL.
Så i prosjektet kan man bruke forskjellige typer NoSQL DB som Cassandra, Mongo DB, Graph DB, HBase etc.
10. Har du erfaring med å jobbe i et cloud computing-miljø? Hvilke fordeler ser du å jobbe i en?
Svar:
Man kan si ja Cloud Computing Environment er klare til å flytte miljø for produksjon, utvikling og testing uten å tenke på å integrere mange forekomster / Linux / windows-servere sammen. Det er forskjellige nettsky-databehandlingstjenester i et marked som AWS (Amazon webtjenester), Azure (Microsoft), GCP (Google Cloud Platform). Cloud computing-tjenesten gir funksjoner nedenfor som fleksibilitet, dvs. miljø vil skalere opp etter behov, Katastrofegjenoppretting ved å ta sikkerhetskopier og øyeblikksbilder, Arbeid hvor som helst med VPN-er, Sikkert miljø og miljøvennlig når det fungerer på råvaremaskinvare, dvs. generelle datamaskiner som har lave kostnader.
Konklusjon
I bloggen over har vi beholdt de mest stilte intervjuspørsmålene på Data Engineer, og hvordan man kan svare på dette ved å gi funksjonspoeng.
Anbefalt artikkel:
Dette har vært en omfattende guide til intervjuer og svar fra Data Engineer, slik at kandidaten enkelt kan slå sammen disse Data Engineer Interview Questions. denne artikkelen består av alle de beste spørsmålene og svarene om dataingeniørintervju. Du kan også se på følgende artikler for å lære mer -
- Viktigste Azure Paas vs Iaas
- Big Data intervju spørsmål
- 5 viktigste spørsmål om Elasticsearch-intervju
- Spørsmål og svar om PIG-intervju
- Topp 5 mest verdifulle spørsmål om datavitenskap