
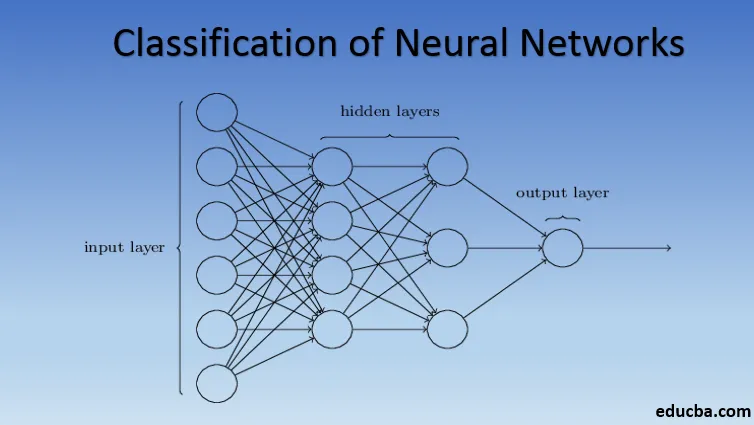
Introduksjon til klassifisering av nevralt nettverk
Nevrale nettverk er den mest effektive måten (ja, du har lest den riktig) for å løse virkelige problemer innen kunstig intelligens. For øyeblikket er det også et av de mye omfattende forskningsområdene innen informatikk at en ny form for nevralt nettverk ville blitt utviklet mens du leser denne artikkelen. Det er hundrevis av nevrale nettverk for å løse problemer som er spesifikke for forskjellige domener. Her skal vi vandre deg gjennom forskjellige typer grunnleggende nevrale nettverk i økende grad av kompleksitet.
Ulike grunnleggende typer i klassifisering av nevrale nettverk
1. Grunne nevrale nettverk (samarbeidsfiltrering)
Nevrale nettverk er laget av grupper av Perceptron for å simulere den nevrale strukturen til den menneskelige hjernen. Grunne nevrale nettverk har et enkelt skjult lag av perceptronet. Et av de vanlige eksemplene på grunne nevrale nettverk er Collaborative Filtering. Det skjulte laget av perceptronet ville bli opplært til å representere likhetene mellom enhetene for å generere anbefalinger. Anbefalingssystem i Netflix, Amazon, YouTube, etc. bruker en versjon av Collaborative-filtrering for å anbefale produktene deres i henhold til brukerens interesse.
2. Flerlags perceptron (Deep Neural Networks)
Nevrale nettverk med mer enn ett skjult lag kalles Deep Neural Networks. Avslørings varsel! Alle følgende nevrale nettverk er en form for dypt nevralt nettverk som er tilpasset / forbedret for å takle domenespesifikke problemer. Generelt hjelper de oss å oppnå universalitet. Gitt nok antall skjulte lag av nevronen, kan et dypt nevralt nettverk omtrentlig dvs. løse ethvert komplekst virkelighetsnært problem.
Universal Approximation Theorem er kjernen i dype nevrale nettverk for å trene og passe til enhver modell. Hver versjon av det dype nevrale nettverket er utviklet av et fullstendig tilkoblet lag med maksimalt sammenslått produkt av matrise-multiplikasjon som er optimalisert av backpropagation-algoritmer. Vi vil fortsette å lære forbedringene som resulterer i forskjellige former for dype nevrale nettverk.
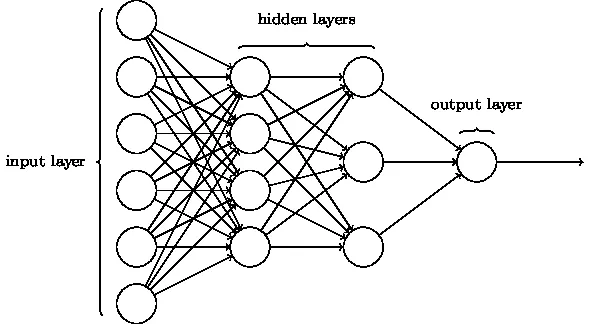
3. Convolutional Neural Network (CNN)
CNN-er er den mest modne formen for dype nevrale nettverk for å produsere den mest nøyaktige, dvs. bedre enn menneskelige resultater i datasyn. CNN-er er laget av lag med viklinger opprettet ved å skanne hver piksel med bilder i et datasett. Når dataene blir tilnærmet lag for lag, begynner CNN å gjenkjenne mønstrene og dermed gjenkjenne objektene på bildene. Disse objektene brukes mye i forskjellige applikasjoner for identifisering, klassifisering, etc. Nyere fremgangsmåter som overføringslæring i CNN har ført til betydelige forbedringer i modellens unøyaktighet. Google Translator og Google Lens er de mest kjente eksemplene på CNN.
Bruken av CNN-er er eksponentiell, ettersom de til og med brukes til å løse problemer som primært ikke er relatert til datasyn. En veldig enkel, men intuitiv forklaring av CNN-er finner du her.
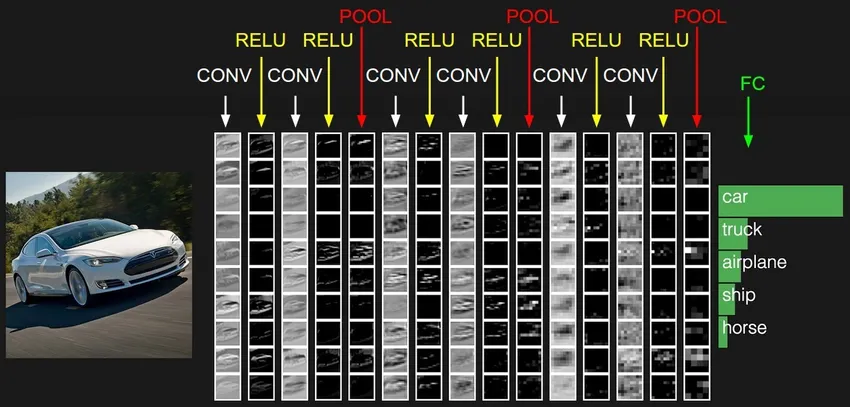
4. Recurrent Neural Network (RNN)
RNN-er er den nyeste formen for dype nevrale nettverk for å løse problemer i NLP. Enkelt sagt, RNNer mater utdataene fra noen få skjulte lag tilbake til inndatasjiktet for å samle og videreføre tilnærmingen til neste iterasjon (epoke) av inndatasettet. Det hjelper også modellen til å lære seg selv og korrigere spådommene raskere i en grad. Slike modeller er svært nyttige for å forstå semantikken i teksten i NLP-operasjoner. Det er forskjellige varianter av RNN-er som Long Short Term Memory (LSTM), Gated Recurrent Unit (GRU), etc. I diagrammet nedenfor mates aktiveringen fra h1 og h2 med henholdsvis inngang x2 og x3.
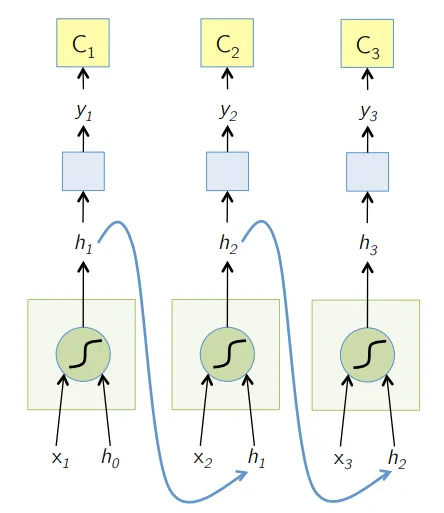
5. Langtidsminne (LSTM)
LSTM-er er designet spesielt for å løse problemet med forsvinnende gradienter med RNN. Forsvinnende graderinger skjer med store nevrale nettverk der gradientene av tapsfunksjonene har en tendens til å bevege seg nærmere null og gjør pauser til nevrale nettverk for å lære. LSTM løser dette problemet ved å forhindre aktiveringsfunksjoner i de tilbakevendende komponentene og ved å deaktivere de lagrede verdiene. Denne lille endringen ga store forbedringer i den endelige modellen, noe som resulterte i at tech-giganter tilpasset LSTM i sine løsninger. Over til den "mest enkle selvforklarende" illustrasjonen av LSTM,
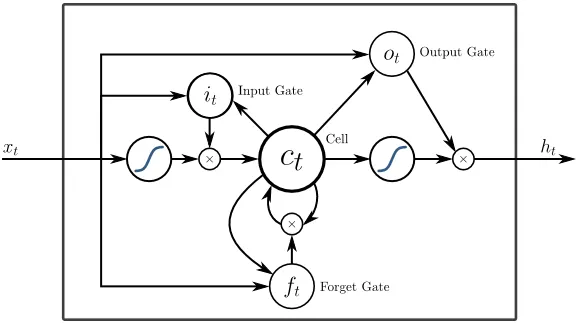
6. Oppmerksomhetsbaserte nettverk
Oppmerksomhetsmodellene tar langsomt over selv de nye RNN-ene i praksis. Oppmerksomhetsmodellene er bygget ved å fokusere på en del av en delmengde av informasjonen de får, og dermed eliminere den overveldende mengden bakgrunnsinformasjon som ikke er nødvendig for oppgaven. Oppmerksomhetsmodeller er bygget med en kombinasjon av myk og hard oppmerksomhet og montering ved tilbakeforplantning av myk oppmerksomhet. Flere oppmerksomhetsmodeller stablet hierarkisk kalles Transformer. Disse transformatorene er mer effektive til å kjøre stablene parallelt slik at de gir moderne resultater med relativt mindre data og tid for opplæring av modellen. En oppmerksomhetsfordeling blir veldig kraftig når den brukes med CNN / RNN og kan produsere tekstbeskrivelse til et bilde som følger.

Tekniske giganter som Google, Facebook osv. Tilpasser raskt oppmerksomhetsmodeller for å bygge sine løsninger.
7. Generative Adversarial Network (GAN)
Selv om dype læringsmodeller gir topp moderne resultater, kan de lure av langt mer intelligente menneskelige kolleger ved å tilføre støy til data fra den virkelige verden. GAN er den siste utviklingen innen dyp læring for å takle slike scenarier. GAN-er bruker uovervåket læring der dype nevrale nettverk trent med dataene generert av en AI-modell sammen med det faktiske datasettet for å forbedre modellens nøyaktighet og effektivitet. Disse motstandsdataene brukes mest for å lure den diskriminerende modellen for å bygge en optimal modell. Den resulterende modellen har en tendens til å være en bedre tilnærming enn det som kan overvinne slik støy. Forskningsinteressen for GAN har ført til mer sofistikerte implementeringer som Conditional GAN (CGAN), Laplacian Pyramid GAN (LAPGAN), Super Resolution GAN (SRGAN), etc.
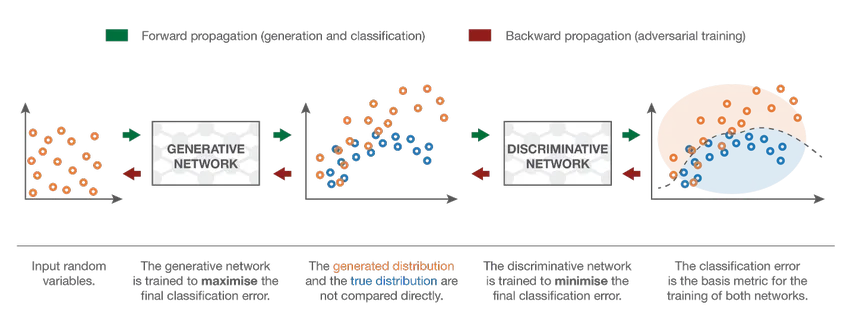
Konklusjon - Klassifisering av nevralt nettverk
De dype nevrale nettverkene har presset datamaskinens grenser. De er ikke bare begrenset til klassifisering (CNN, RNN) eller spådommer (Collaborative Filtering), men til og med generering av data (GAN). Disse dataene kan variere fra den vakre formen for kunst til kontroversielle dype forfalskninger, men de overgår mennesker med en oppgave hver dag. Derfor bør vi også vurdere AI-etikk og -påvirkninger mens vi jobber hardt for å bygge en effektiv nevralt nettverksmodell. På tide med en fin infografikk om nevrale nettverk.
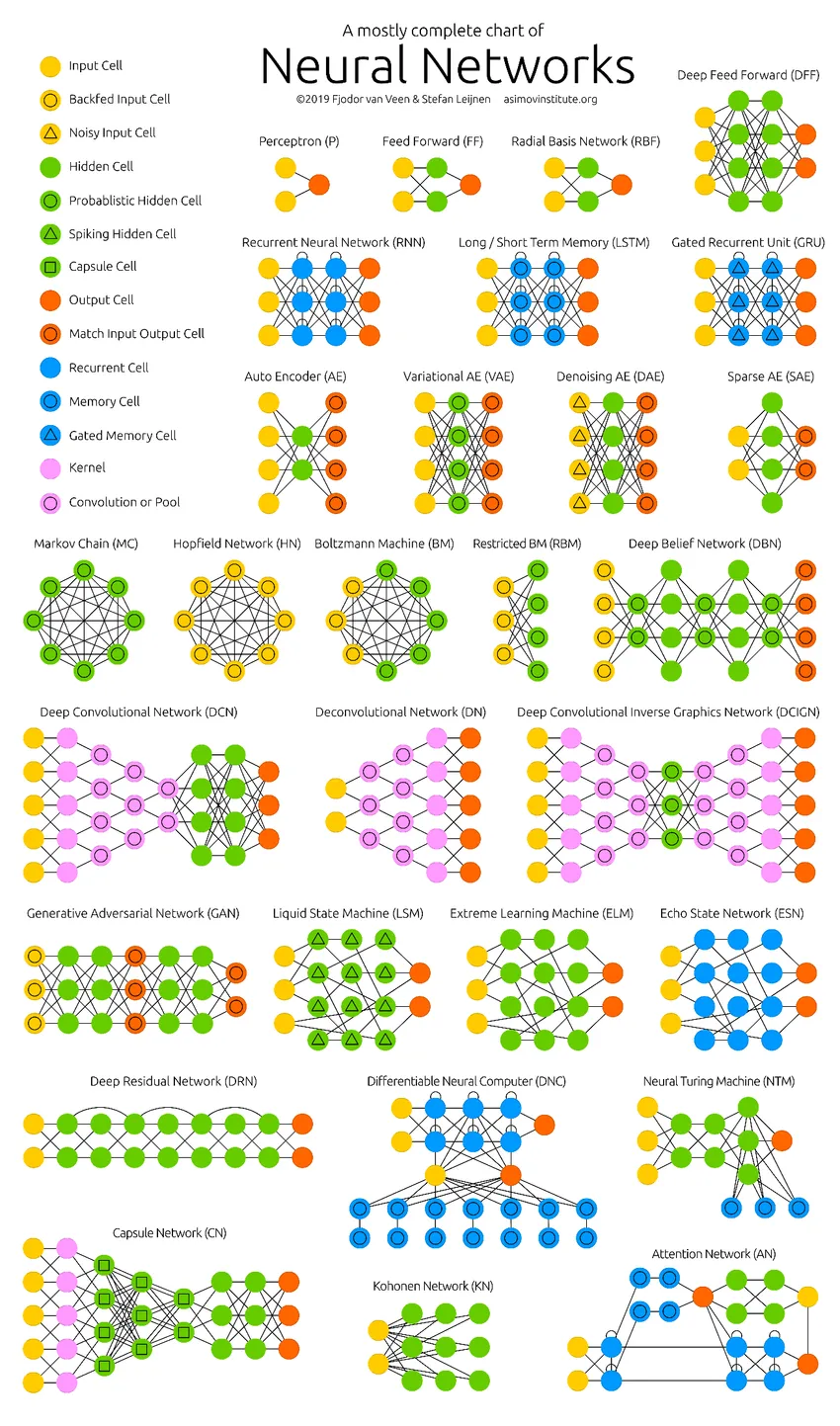
Anbefalte artikler
Dette er en guide til Classification of Neural Network. Her diskuterte vi de forskjellige typene grunnleggende nevrale nettverk. Du kan også gå gjennom artiklene våre for å lære mer-
- Hva er nevrale nettverk?
- Nevrale nettverksalgoritmer
- Nettverksskanneverktøy
- Gjentatte nevrale nettverk (RNN)
- Topp 6 sammenligninger mellom CNN vs RNN