

Introduksjon til Map Join in Hive
Map join er en funksjon som brukes i Hive-spørsmål for å øke effektiviteten i forhold til hastighet. Bli med er en betingelse som brukes til å kombinere dataene fra to tabeller. Så når vi utfører en normal sammenføyning, sendes jobben til en kart-reduser oppgave som deler hovedoppgaven i to trinn - “Kartfase” og “Reduser scene”. Karttrinnet tolker inndataene og returnerer utdata til reduksjonsstadiet i form av nøkkelverdipar. Denne neste går gjennom shuffle-scenen der de blir sortert og kombinert. Reduseren tar denne sorterte verdien og fullfører samarbeidsjobben.
En tabell kan lastes helt inn i minnet i en mapper og uten å måtte bruke Map / Reducer-prosessen. Den leser dataene fra det mindre bordet og lagrer dem i en hash-tabell i minnet og deretter serialiserer den til hasjminnefilen og reduserer tiden betydelig. Det er også kjent som Map Side Join in Hive. I utgangspunktet innebærer det å utføre sammenføyninger mellom to tabeller ved å kun bruke kartfasen og hoppe over reduksjonsfasen. En tidsnedgang i beregningen av spørsmålene dine kan observeres hvis de regelmessig bruker en liten tabellfelt.
Syntaks for Map Join in Hive
Hvis vi ønsker å utføre et sammenføyningssøk ved hjelp av map-join, må vi spesifisere et nøkkelord “/ * + MAPJOIN (b) * /” i utsagnet som nedenfor:
>SELECT /*+ MAPJOIN(c) */ * FROM tablename1 t1 JOIN tablename2 t2 ON (t1.emp_id = t2.emp_id);
For dette eksemplet må vi lage 2 tabeller med navn tablename1 og tablename2 som har 2 kolonner: emp_id og emp_name. En skal være en større fil og en bør være en mindre.
Før du kjører spørringen, må vi sette egenskapen nedenfor til sann:
hive.auto.convert.join=true
Samlingsspørringen for kartforbindelse er skrevet som ovenfor, og resultatet vi får er:
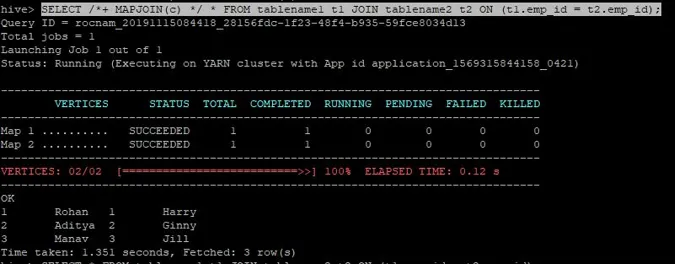
Søket ble fullført på 1.351 sekunder.
Eksempler på Map Join in Hive
Her er følgende eksempler nevnt nedenfor
1. Kart bli med eksempel
For dette eksempelet, la oss lage 2 tabeller som heter tabell1 og tabell2 med henholdsvis 100 og 200 poster. Du kan henvise kommandoen og skjermbildene nedenfor for å utføre det samme:
>CREATE TABLE IF NOT EXISTS table1 ( emp_id int, emp_name String, email_id String, gender String, ip_address String) row format delimited fields terminated BY ', ' tblproperties("skip.header.line.count"="1");
>CREATE TABLE IF NOT EXISTS table2 ( emp_id int, emp_name String) row format delimited fields terminated BY ', ' tblproperties("skip.header.line.count"="1");

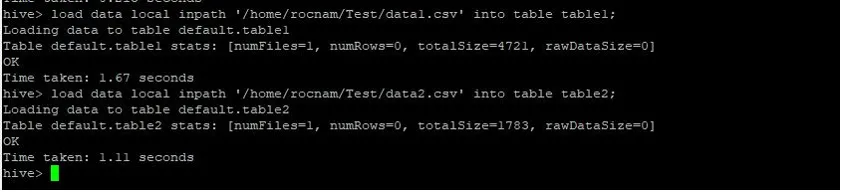
Nå laster vi postene i begge tabellene ved hjelp av kommandoer nedenfor:
>load data local inpath '/relativePath/data1.csv' into table table1;
>load data local inpath '/relativePath/data2.csv' into table table2;
La oss utføre et vanlig kartforbindelsespørsmål på ID-ene deres som vist nedenfor og bekrefte tiden det tar for det samme:
>SELECT /*+ MAPJOIN(table2) */ table1.emp_name, table1.emp_id, table2.emp_id FROM table1 JOIN table2 ON table1.emp_name = table2.emp_name;
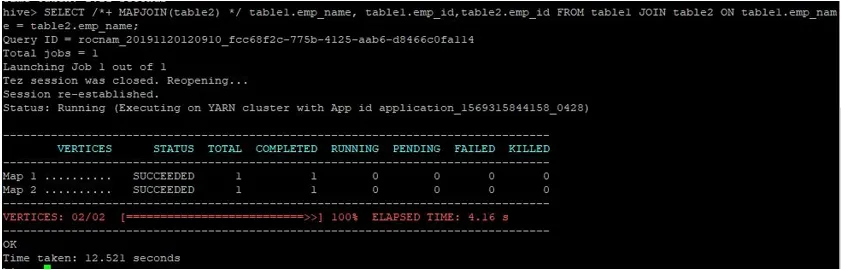
Som vi kan se, tok et normalt kart-sammenføyningsspørsmål 12.521 sekunder.
2. Eksempel på sammenføyning av bøtte-kart
La oss nå bruke Bucket-map join for å kjøre det samme. Det er noen få begrensninger som må følges for bucketing:
- Skuffene kan forbindes med hverandre bare hvis den totale bøttene til en tabell er flere av antall bøtter i den andre tabellen.
- Må ha bucketed-tabeller for å utføre bucketing. La oss derfor lage det samme.
Følgende er kommandoene som brukes til å lage bøtte-tabeller tabell 1 og tabell2:
>>CREATE TABLE IF NOT EXISTS table1_buk (emp_id int, emp_name String, email_id String, gender String, ip_address String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ', ';
>CREATE TABLE IF NOT EXISTS table2_buk ( emp_id int, emp_name String) clustered by(emp_name) into 8 buckets row format delimited fields terminated BY ', ' ;

Vi skal sette inn de samme postene fra tabell1 i disse bøttede tabellene også:
>insert into table1_buk select * from table1;
>insert into table2_buk select * from table2;
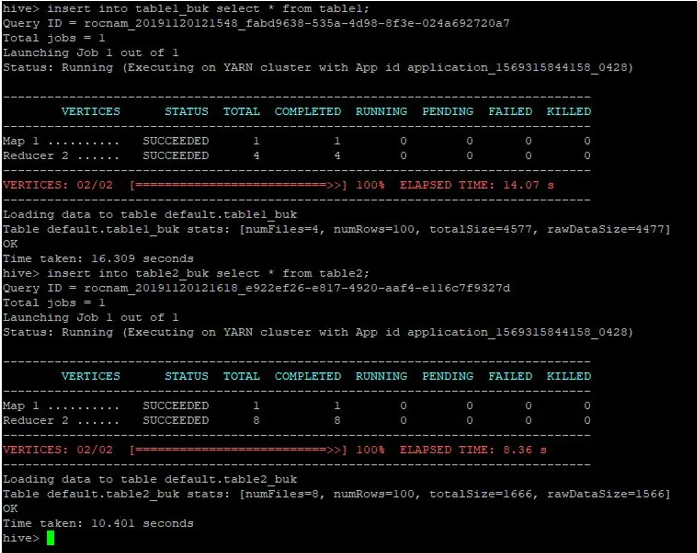
Nå som vi har våre to bøttebord, la oss utføre en bøtte-kart-sammenføyning på disse. Den første tabellen har 4 bøtter, mens den andre tabellen har 8 bøtter opprettet i samme kolonne.
For at bøtte-kart-sammenføyningssøket skal fungere, bør vi sette egenskapen nedenfor til å være sann i bikuben:
set hive.optimize.bucketmapjoin = true
>SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name, table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
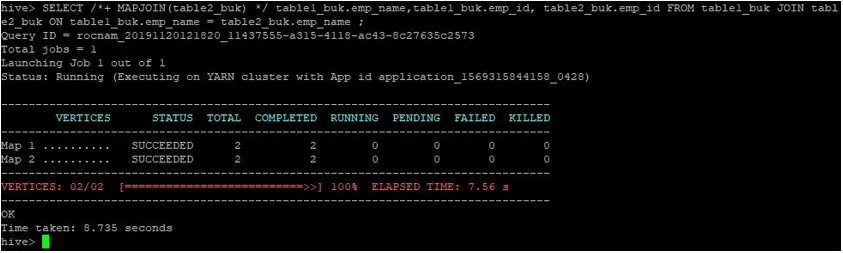
Som vi kan se, ble spørringen fullført på 8.735 sekunder, noe som er raskere enn et vanlig kartforbindelse.
3. Sorter sammenføyningsbøttekart for å være med (SMB)
SMB kan utføres på bøttebord som har samme antall bøtter, og hvis tabellene må sorteres og bøttes på sammenføyningskolonner. Mapper-nivå slutter seg til disse skuffene tilsvarende.
Samme som i bøtte-kart-sammenføyning, det er 4 bøtter for bord1 og 8 bøtter for bord2. For dette eksemplet skal vi lage en annen tabell med 4 bøtter.
For å kjøre SMB-spørring, må vi angi følgende bikubeegenskaper som vist nedenfor:
Hive.input.format = org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
hive.optimize.bucketmapjoin = sant;
hive.optimize.bucketmapjoin.sortedmerge = true;
For å utføre SMB-sammenkobling må det sorteres data i henhold til sammenføyningskolonnene. Derfor overskriver vi dataene i tabell1 som er skuffet som nedenfor:
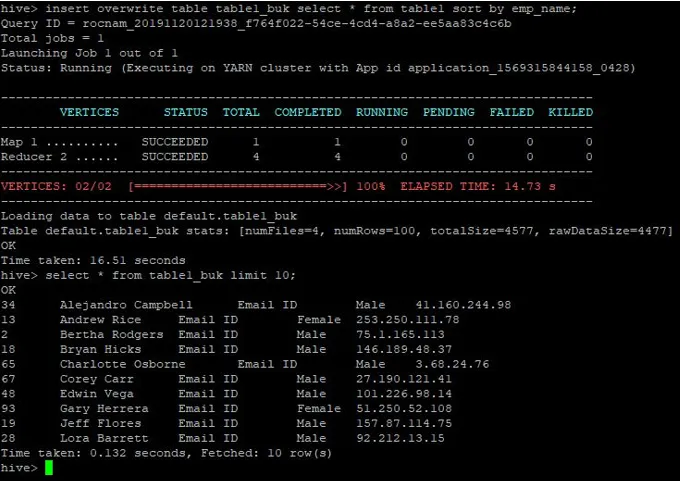
>insert overwrite table table1_buk select * from table1 sort by emp_name;
Dataene er sortert nå som kan sees i skjermbildet nedenfor:
Vi skal også overskrive data i bucketed tabell2 som nedenfor:
>insert overwrite table table2_buk select * from table2 sort by emp_name;

La oss utføre sammenføyningen for over 2 tabeller som følger:
>SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name, table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
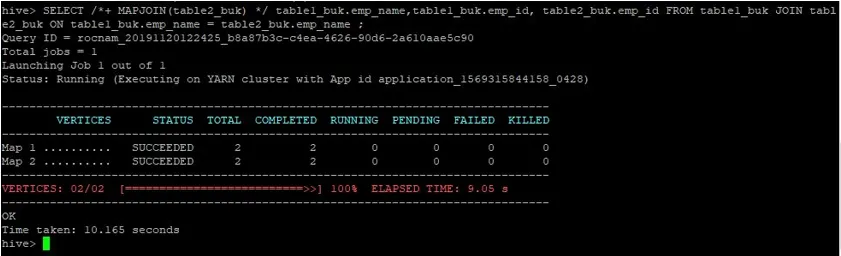
Vi kan se at spørringen tok 10.165 sekunder, noe som igjen er bedre enn et vanlig kartforbindelse.
La oss nå lage en annen tabell for tabell2 med 4 bøtter og de samme dataene sortert med emp_name.
>CREATE TABLE IF NOT EXISTS table2_buk1 (emp_id int, emp_name String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ', ' ;
>insert overwrite table table2_buk1 select * from table2 sort by emp_name;
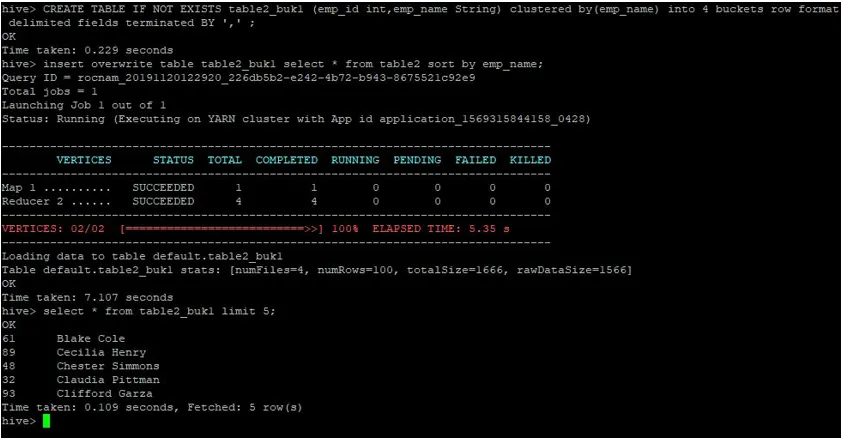
Tatt i betraktning at vi nå har begge bord med fire bøtter, la oss igjen utføre et spørsmål om sammenføyning.
>SELECT /*+ MAPJOIN(table2_buk1) */table1_buk.emp_name, table1_buk.emp_id, table2_buk1.emp_id FROM table1_buk JOIN table2_buk1 ON table1_buk.emp_name = table2_buk1.emp_name ;
Spørsmålet har tatt 8.851 sekunder igjen raskere enn det vanlige kartforbindelsessøket.
Fordeler
- Kartforbindelse reduserer tiden det tar å sortere og slå sammen prosesser som foregår i blandingen og reduserer trinnene og minimerer også kostnadene.
- Det øker effektiviteten til oppgaven.
begrensninger
- Den samme tabellen / aliaset er ikke tillatt brukt til å bli med i forskjellige kolonner i samme spørring.
- Kartforespørsel kan ikke konvertere Full ytre sammenføyninger til kartsideforbindelser.
- Kartforbindelse kan bare utføres når et av bordene er lite nok til at det kan passe til minnet. Derfor kan det ikke utføres der tabelldataene er enorme.
- En venstre sammenføyning er mulig å gjøre til et kartforbindelse bare når riktig bordstørrelse er liten.
- En høyre sammenføyning er mulig å gjøre til et kartforbindelse bare når den venstre tabellstørrelsen er liten.
Konklusjon
Vi har prøvd å ta med de best mulige punktene i Map Join in Hive. Som vi har sett ovenfor, fungerer Map-side-sammenføyning best når en tabell har mindre data slik at jobben blir fullført raskt. Tiden det tar for spørsmålene som vises her, avhenger av størrelsen på datasettet, og tiden som vises her er bare for analyse. Kartoppkobling kan enkelt implementeres i sanntidsapplikasjoner siden vi har enorme data og dermed reduserer I / O-nettverkstrafikken.
Anbefalte artikler
Dette er en guide til Map Join in Hive. Her diskuterer vi eksemplene på Map Join in Hive sammen med fordelene og begrensningene. Du kan også se på følgende artikkel for å lære mer -
- Bli med i Hive
- Hive innebygde funksjoner
- Hva er en bikube?
- Hive-kommandoer