

Forskjellen mellom Hadoop og HBase
Hadoop er et Java-rammeverk med åpen kildekode, brukt til å håndtere og behandle en enorm mengde strukturerte og ustrukturerte data. Hadoop er massivt skalerbar, og blir derfor brukt til å behandle arbeidsdata for store data. Store data lagres, åpnes og behandles i den pålitelige og utvidbare klyngen. HBase (Hadoop Database) er en ikke-relasjonell og ikke bare SQL, dvs. NoSQL-database som kjører på toppen av Hadoop som et distribuert og skalerbart store datalager. Det er en åpen kildekodedatabase der data lagres i form av rader og kolonner, i den cellen er et skjæringspunkt mellom kolonner og rader.
Nedenfor er kjernekomponentene i Hadoop arkitektur:
- Hadoop Distribuert filsystem (HDFS): Hadoop inkluderer et distribuert lagringssystem, Hadoop Distribuert filsystem (HDFS). HDFS er master-slave-arkitekturen som lagrer data over hele klyngen. Data distribuert på flere slavetoder av hovednoden i skjemablokken. Hovednoden heter Namenode og slaveknuter kalles Datanode. HDFS kan enkelt utvides og lagrer en enorm mengde data på Datanodes. HDFS har en konfigurerbar replikasjonsfaktor med standardverdi 3 som kan redigeres.
- MapReduce: MapReduce er et programmeringsparadigme som prosesser parallelt på et stort antall datasett over nettverket. MapReduce refererer til to forskjellige oppgaver: kartlegge inndatadataene der data delt inn i en delmengde av data kalt tuple og redusere oppgave tar disse tuplene fra kartet som input og kombineres for å danne utgangen fra originalen.
- Garn: YARN står for Enda en ressursnavigator som beregner ressurser som administrerer CPU og minne, planlegging av ressursforespørsler.
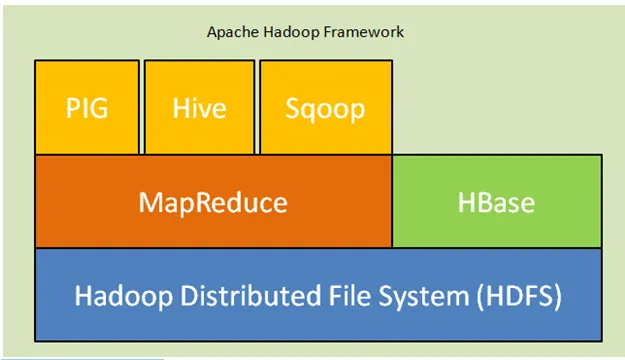
Fig. Apache Hadoop Framework
Regionserver serverer data for lese- / skriveoperasjoner. Alle HBase-dataene lagres i HDFS-filen. HDFS Datanode lagrer dataene som regionserveren administrerer. HDFS Namenode oppbevarer metadatainformasjon for alle fysiske datablokkene som inneholder filene.
Versjonering brukes til å spore celleendringer, som holder oversikten over innholdsversjonen. Fra det kan enhver versjon av innhold hentes. Hver celleverdi inkluderer attributten 'versjon' med hensyn til tidsstemplet for å hente cellen. Hver verdi på kartet er en uavbrutt rekke byte. Kartet indekseres med en radtast, kolonnetast og en tidsstempel. Arkitekturen til HBase er svært skalerbare, sparsomme, distribuerte, vedvarende og flerdimensjonale sorterte kart.
Sammenligning mellom hodet og hodet mellom Hadoop vs HBase (Infographics)
Nedenfor er topp 7 forskjellen mellom Hadoop vs HBase
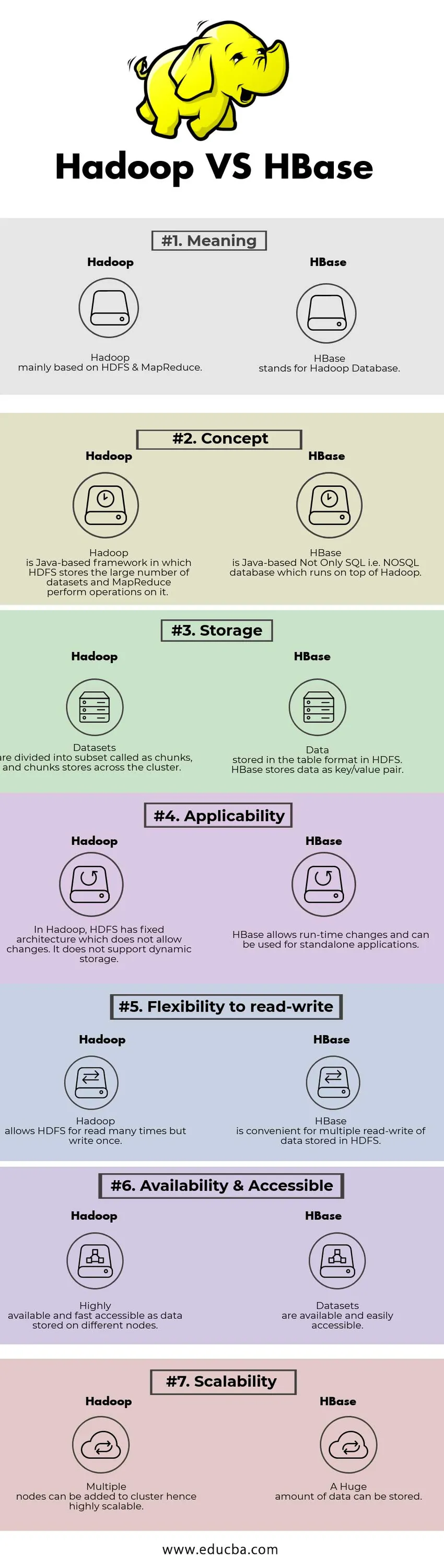
Viktige forskjeller mellom Hadoop vs HBase
Forskjellen mellom Hadoop og HBase er forklart i punktene presentert nedenfor:
- Hadoop er ikke egnet for Online analytisk prosessering (OLAP) og HBase er en del av Hadoop-økosystemet som gir tilfeldig tilgang til sanntid (lese / skrive) til data i Hadoop-filsystemet.
- Hadoop-rammeverket er feiltolerant av design og støtter rask dataoverføring mellom noder selv under systemfeil. HBase er en ikke-relasjonell og åpen kildekode Not-Only-SQL-database som kjører på toppen av Hadoop. HBase er under CP-type CAP (konsistens, tilgjengelighet og partisjonstoleranse) teorem.
- Hadoop er best egnet for å utføre batchanalyse. En av de største ulempene er imidlertid manglende evne til å utføre sanntidsanalyser, det mest populære kravet til IT-bransjen. HBase kan derimot håndtere store datasett og er ikke passende for batchanalyse. I stedet brukes den til å skrive / lese data fra Hadoop i sanntid.
- Både Hadoop og HBase er i stand til å behandle strukturerte, semistrukturerte så vel som ustrukturerte data. I Hadoop mangler HDFS en prosessor i minnet som bremser prosessen med dataanalyse; som det bruker vanlig gammel MapReduce for å gjøre det. HBase skryter tvert imot av en prosessormotor i minnet som drastisk øker hastigheten på lese / skrive.
- Hadoop er veldig gjennomsiktig i utførelsen av dataanalyse. HBase, derimot, som en NoSQL-database i tabellformat, henter verdier ved å sortere dem under forskjellige nøkkelverdier.
Hadoop vs HBase sammenligningstabell
| GRUNN FOR SAMMENLIGNING | Hadoop | HBase |
| Betydning | Hadoop hovedsakelig basert på HDFS & MapReduce. | HBase står for Hadoop Database. |
| Konsept | Hadoop er et Java-basert rammeverk der HDFS lagrer det store antall datasett og MapReduce utfører operasjoner på det. | HBase er Java-basert ikke bare SQL, dvs. NoSQL-database som kjører på toppen av Hadoop. |
| Oppbevaring | Datasett er delt inn i delsett som kalles biter, og biter butikker over hele klyngen. | Data lagret i tabellformatet i HDFS. HBase lagrer data som nøkkel / verdipar. |
| Gyldighet | I Hadoop har HDFS fast arkitektur som ikke tillater endringer. Den støtter ikke dynamisk lagring. | HBase tillater endringer i løpet av tiden og kan brukes til frittstående applikasjoner. |
| Fleksibilitet til å lese-skrive | Hadoop lar HDFS lese mange ganger, men skriver en gang. | HBase er praktisk for flere lesing av data som er lagret i HDFS |
| Tilgjengelighet og tilgjengelige | Svært tilgjengelig og raskt tilgjengelig som data lagret på forskjellige noder. | Datasett er tilgjengelige og lett tilgjengelige |
| skalerbarhet | Flere noder kan legges til klyngen, derav meget skalerbar. | En enorm datamengde kan lagres. |
Konklusjon - Hadoop vs HBase
Hadoop-arkitektur hovedsakelig basert på HDFS og MapReduce. HBase er den støttende komponenten i Hadoop-systemet. HBase er i stand til å være vert for enorme tabeller og gir rask tilfeldig tilgang til tilgjengelige data mens HDFS er egnet for lagring av store filer. Både Hadoop og HBase gir rask tilgang til data, men med HBase kan lese / skriveoperasjoner utføres og for HDFS lese mange ganger og en gang kan skrivingen utføres. Denne artikkelen beskrev forståelsen av Hadoop og HBase, kort fremhevet funksjoner og sammenlignet klokt.
Anbefalt artikkel
- Apache Hadoop vs Apache Spark | Topp 10 sammenligninger du må vite!
- Hadoop vs Hive - Finn ut de beste forskjellene
- HBase vs Cassandra - Hvilken som er bedre (Infographics)
- Topp 12 sammenligning av Apache Hive vs Apache HBase (Infographics)
- Hadoop vs Spark: Hva er funksjonene