

Introduksjon til ANOVA i R
Følgende artikkel ANOVA i R gir en oversikt for å sammenligne middelverdien til forskjellige grupper. En analyse av variasjon (ANOVA) er en veldig vanlig teknikk som brukes for å sammenligne middelverdien til forskjellige grupper. ANOVA-modellen brukes til hypotesetesting, der en viss antagelse eller parameter genereres for en populasjon og den statistiske metoden brukes for å bestemme om hypotesen er sann eller usann.
Hypotesen er avledet fra etterforskerens antagelse og tilgjengelige informasjon om befolkningen. ANOVA kalles en analyse av variasjon og brukes til hypotesetesting der det kreves måling av middel til en variabel i flere uavhengige grupper.
For eksempel, i et laboratorium for å studere eller finne opp et nytt medisin mot overvekt, vil forskere sammenligne resultatet av eksperimentell og standardbehandling. I en fedmeundersøkelse kan verdifulle resultater avledes når den gjennomsnittlige overvektstallet i befolkningen kan sammenlignes i forskjellige aldersgrupper. I dette tilfellet ønsker man å observere gjennomsnittlig overvekt blant forskjellige aldersgrupper som alder (5 til 18), (19, 35) og (36 til 50). ANOVA-metoden brukes da det er mer enn to grupper som er uavhengige. ANOVA-metoden brukes til å sammenligne den gjennomsnittlige overvekten til de uavhengige gruppene. Funksjonen aov () brukes og Syntax er aov (formel, data = dataframe). I denne artikkelen skal vi lære om ANOVA-modellen og videre diskutere enveis og toveis ANOVA-modell sammen med eksempler.
Hvorfor ANOVA?
- Denne teknikken brukes til å svare på hypotesen mens du analyserer flere datagrupper. Det er flere statistiske tilnærminger, men ANOVA i R brukes når sammenligning må gjøres på mer enn to uavhengige grupper, som i vårt forrige eksempel tre forskjellige aldersgrupper.
- ANOVA-teknikk måler middelet til de uavhengige gruppene for å gi forskere resultatet av hypotesen. For å få nøyaktige resultater, må det tas hensyn til utvalgsmetoder, prøvestørrelse og standardavvik fra hver enkelt gruppe.
- Det er mulig å observere gjennomsnittet individuelt for hver av de tre gruppene for sammenligning. Imidlertid har denne tilnærmingen begrensninger og kan vise seg å være feil fordi disse tre sammenligningene ikke vurderer totale data og dermed kan føre til type 1-feil. R gir oss funksjonen til å utføre ANOVA-analysen for å undersøke variabilitet blant de uavhengige datagruppene. Det er fem stadier av å utføre ANOVA-analysen. I det første trinnet er data arrangert i csv-format og kolonnen genereres for hver variabel. En av kolonnene vil være en avhengig variabel og gjenværende er den uavhengige variabelen. I andre trinn blir dataene lest i R studio og navngitt på riktig måte. I tredje trinn er et datasett knyttet til individuelle variabler og lest av minnet. Til slutt blir ANOVA i R definert og analysert. I seksjonene nedenfor har jeg gitt et par eksempler på casestudier der ANOVA-teknikker skal brukes.
- Seks insektmidler ble testet på 12 felt hver, og forskerne teller antall feil som ble igjen i hvert felt. Nå trenger bøndene å vite om insektmidlene utgjør noen forskjell, og i så fall hvilken som de bruker best. Du svarer på dette spørsmålet ved å bruke aov () -funksjonen for å utføre en ANOVA.
- Femti pasienter fikk en av fem kolesterolreduserende medikamentelle behandlinger (trt). Tre av behandlingsbetingelsene involverte det samme medikamentet som ble administrert som 20 mg en gang per dag (1 gang) 10 mg to ganger per dag (2 ganger) 5 mg fire ganger per dag (4 ganger). De to gjenværende forholdene (drugD and drugE) representerte konkurrerende medisiner. Hvilken medikamentell behandling ga størst kolesterolreduksjon (respons)?
ANOVA enveis
- Enveis-metoden er en av grunnleggende ANOVA-teknikker der variansanalyse brukes og middelverdien av flere populasjonsgrupper sammenlignes.
- Enveis ANOVA fikk navnet på grunn av tilgjengeligheten av enveis klassifiserte data. I en enveis ANOVA enkeltavhengig variabel og en eller flere uavhengige variabler kan være tilgjengelig.
- For eksempel vil vi utføre ANOVA-teknikken på kolesteroldatasettet. Datasettet består av to variabler trt (som er behandlinger på 5 forskjellige nivåer) og responsvariabler. Uavhengig variabel - grupper av medikamentell behandling, avhengig variabel - middel for 2 eller flere grupper ANOVA. Fra disse resultatene kan du bekrefte at det var bedre å ta 5 mg dosene 4 ganger om dagen enn å ta en dose på tjue mg en gang om dagen. Medikament D har bedre effekter sammenlignet med det medikamentet E
Medikament D gir bedre resultater hvis det tas i 20 mg doser sammenlignet med medikament E
Bruker kolesteroldatasett i multkompakkepakkeninstall.packages('multcomp')
library(multcomp)
str(cholesterol)
attach(cholesterol)
aov_model <- aov(response ~ trt)
ANOVA F-testen for behandling (trt) er betydelig (p <0, 0001), og gir bevis for at de fem behandlingene
# er ikke alle like effektive.
sammendrag (aov_model)
frakobling (kolesterol)

Funksjonen plotmeans () i gplots-pakken kan brukes til å produsere en graf over gruppemiddel og deres tillitsintervaller Dette viser tydelig behandlingsforskjellerinstall.packages('gplots')
library(gplots)
plotmeans(response ~ trt, xlab="Treatment", ylab="Response",
main="Mean Plot\nwith 95% CI")
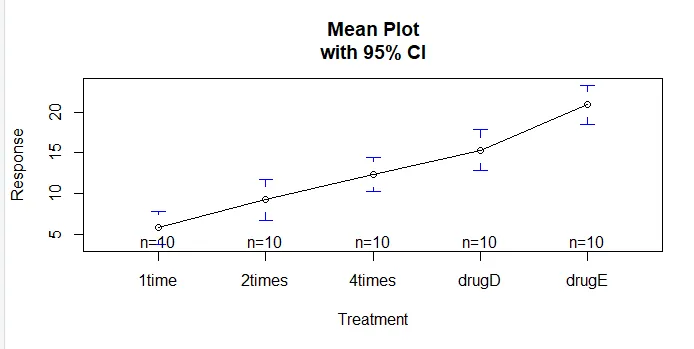
La oss undersøke utdataene fra TukeyHSD () for parvise forskjeller mellom gruppemiddel
TukeyHSD (aov_model)
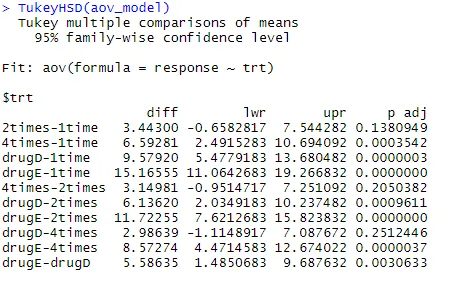
Den gjennomsnittlige kolesterolreduksjonen 1 gang og 2 ganger er ikke vesentlig forskjellig fra hverandre (p = 0, 118), mens forskjellen mellom 1 gang og 4 ganger er betydelig forskjellig (p <0, 001).
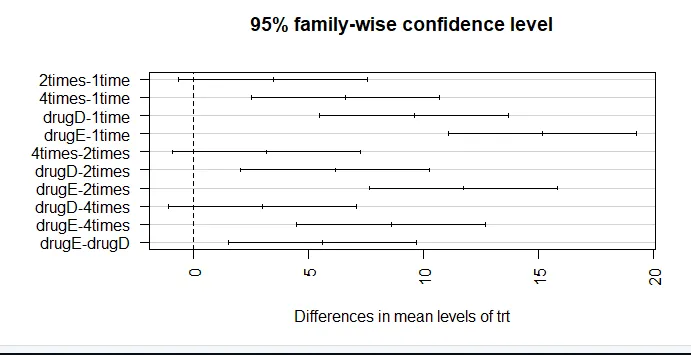
par (mar = c (5, 8, 4, 2)) # økning tomt venstre marginal (TukeyHSD (aov_model), las = 2)
Tillit til resultater avhenger av i hvilken grad dataene dine tilfredsstiller forutsetningene som ligger til grunn for de statistiske testene. I en enveis ANOVA antas den avhengige variabelen å være normalt fordelt og ha lik varians i hver gruppe. Du kan bruke et QQ-plot for å vurdere biblioteket om normalitetsforutsetninger (bil).
QQ-plott (lm (respons ~ trt, data = kolesterol), simulere = SANN, hoved = ”QQ Plot”, etiketter = FALSE)
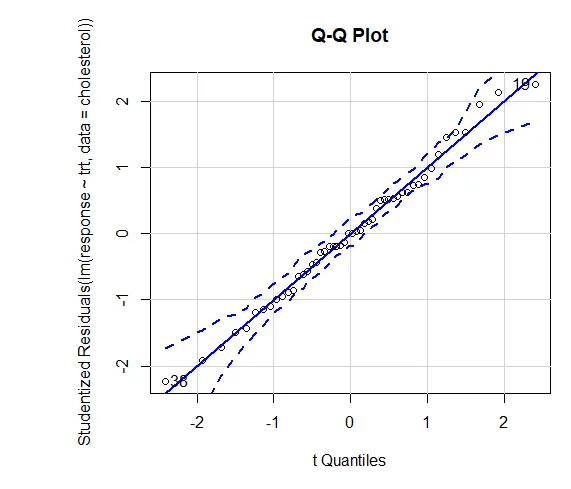
Stiplet linje = 95% konfidenskonvolutt, noe som antyder at normalitetsforutsetningen er oppfylt ganske bra ANOVA antar at avvik er like på tvers av grupper eller prøver. Bartlett-testen kan brukes til å bekrefte den antagelsen
bartlett.test (respons ~ trt, data = kolesterol). Bartlett's test indikerer at variansene i de fem gruppene ikke skiller seg signifikant (p = 0, 97).
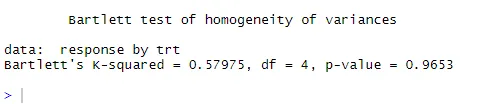
ANOVA er også følsom for outliers-test for outliers med funksjonen outlierTest () i bilpakken. Du trenger kanskje ikke å kjøre denne pakken for å oppdatere bilbiblioteket ditt.update.packages(checkBuilt = TRUE)
install.packages("car", dependencies = TRUE)
library(car)
outlierTest(aov_model)
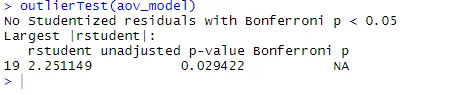
Fra utgangen kan du se at det ikke er noen indikasjon på skiller i kolesteroldataene (NA oppstår når p> 1). Hvis vi tar QQ-plottet, Bartlett's test og en tidligere test sammen, ser det ut til at dataene passer til ANOVA-modellen.
To-veis Anova
En annen variabel legges til i toveis ANOVA-testen. Når det er to uavhengige variabler, må vi bruke toveis ANOVA snarere enn enveis ANOVA-teknikk som ble brukt i forrige tilfelle der vi hadde en kontinuerlig avhengig variabel og mer enn en uavhengig variabel. For å verifisere toveis ANOVA, må flere forutsetninger tilfredsstilles.
- Tilgjengeligheten av uavhengige observasjoner
- Observasjoner skal normalt distribueres
- Variasjoner skal være like i observasjoner
- Outliers skal ikke være til stede
- Uavhengige feil
For å verifisere den toveis ANOVA blir en annen variabel kalt BP lagt til i datasettet. Variabelen indikerer hastigheten på blodtrykk hos pasienter. Vi vil verifisere om det er noen statistisk forskjell mellom BP og dosering gitt til pasientene.
df <- read.csv (“file.csv”)
df
anova_two_way <- aov (respons ~ trt + BP, data = df)
sammendrag (anova_two_way)
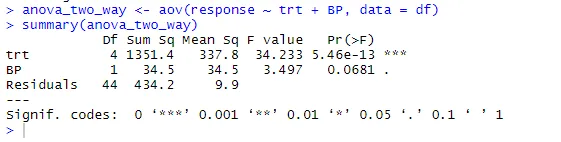
Fra utgangen kan det konkluderes at både trt og BP er statistisk forskjellige fra 0. Derfor kan Null-hypotesen avvises.
Fordelene med ANOVA i R
ANOVA-test bestemmer forskjellen i gjennomsnitt mellom to eller flere uavhengige grupper. Denne teknikken er veldig nyttig for analyse av flere elementer, noe som er viktig for markedsanalyse. Ved å bruke ANOVA-testen kan man få nødvendig innsikt fra dataene. For eksempel under en produktundersøkelse der flere opplysninger som handlelister, kundelignende og ikke-likte blir samlet inn fra brukerne. ANOVA-testen hjelper oss å sammenligne grupper av befolkningen. Gruppen kan enten være Mann mot Kvinne eller forskjellige aldersgrupper. ANOVA-teknikk hjelper med å skille mellom middelverdiene for forskjellige grupper av befolkningen som faktisk er forskjellige.
Konklusjon - ANOVA i R
ANOVA er en av de mest brukte metodene for hypotesetesting. I denne artikkelen har vi utført en ANOVA-test på datasettet som består av femti pasienter som fikk kolesterolreduserende medikamentell behandling og har videre sett hvordan toveis ANOVA kan utføres når en ekstra uavhengig variabel er tilgjengelig.
Anbefalte artikler
Dette er en guide til ANOVA i R. Her diskuterer vi Enveis og toveis Anova-modell sammen med eksempler og fordeler med ANOVA. Du kan også gå gjennom andre foreslåtte artikler -
- Regresjon vs ANOVA
- Hva er SPSS?
- Hvordan tolke resultater ved bruk av ANOVA-test
- Funksjoner i R