

Introduksjon til metodikk for gruvedrift
Data øker daglig i enorm skala. Men all data samlet eller samlet er ikke nyttig. Meningsfulle data må skilles fra støyende data (meningsløse data). Denne separasjonsprosessen gjøres av data mining.
Hva er datamining?
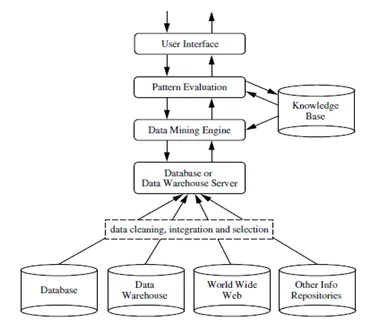
Data mining er en prosess for å hente ut nyttig informasjon eller kunnskap fra en enorm mengde data (eller big data). Gapet mellom data og informasjon er redusert ved å bruke forskjellige data mining-verktøy. Data mining kan også bli referert til som kunnskapsfunn fra data eller KDD .
Kilder: - www.ques10.com
Data mining kan utføres på forskjellige typer databaser og informasjonslagre som relasjonsdatabaser, datavarehus, transaksjonsdatabaser, datastrømmer og mange flere.
Ulike metoder for datautvinning:
Det er mange metoder som brukes for Data Mining, men det avgjørende trinnet er å velge riktig metode fra dem i henhold til virksomheten eller problemstillingen. Disse data mining metodene hjelper til med å forutsi fremtiden og deretter ta beslutninger deretter. Disse hjelper også med å analysere markedsutviklingen og øke selskapets inntekter.
Noen metoder for utvinning av data er:
- assosiasjon
- Klassifisering
- Clustering Analyse
- Prediksjon
- Sekvensielle mønstre eller mønstersporing
- Beslutningstrær
- Tidligere analyse eller avviksanalyse
- Nevrale nettverket
La oss forstå alle metoder for data mining en etter en.
1. Forening:
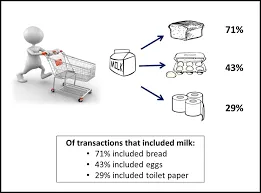
Det er en metode som brukes for å finne en sammenheng mellom to eller flere elementer ved å identifisere det skjulte mønsteret i datasettet og dermed også kalt som relasjonsanalyse . Denne metoden brukes i markedskurvanalyse for å forutsi atferden til kunden.
Anta at markedssjefen i et supermarked ønsker å bestemme hvilke produkter som ofte kjøpes sammen.
Som et eksempel,
Kjøper (x, "øl") -> kjøper (x, "chips") (støtte = 1%, selvtillit = 50%)
- Her representerer x en kunde som kjøper øl og chips sammen.
- Tillit viser sikkerhet for at hvis en kunde kjøper en øl, er det 50% sjanse for at han / hun vil kjøpe sjetongene også.
- Støtte betyr at 1% av alle transaksjoner under analyse viste at øl og chips ble kjøpt sammen.
Mange lignende eksempler som brød og smør eller datamaskin og programvare kan tas i betraktning.
Det er to typer tilknytningsregler:
- Endimensjonal assosieringsregel: Disse reglene inneholder et enkelt attributt som gjentas.
- Flerdimensjonal assosieringsregel: Disse reglene inneholder flere attributter som gjentas.
https://bit.ly/2N61gzR
2. Klassifisering:
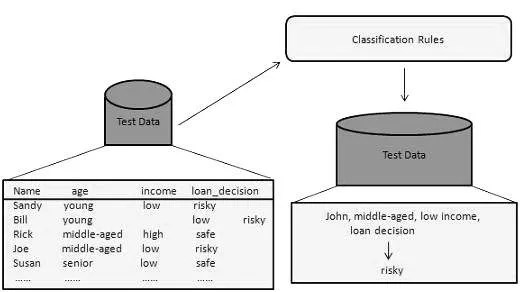
Denne data mining-metoden brukes til å skille elementene i datasettene i klasser eller grupper. Det hjelper å nøyaktig forutsi atferden til elementer i gruppen. Det er en to-trinns prosess:
- Læringstrinn (opplæringsfase): I denne bygger en klassifiseringsalgoritme klassifisereren ved å analysere et treningssett.
- Klassifiseringstrinn: Testdata brukes for å estimere nøyaktigheten eller presisjonen av klassifiseringsreglene.
For eksempel bruker et bankselskap for å identifisere lånesøkere med lav, middels eller høy kredittrisiko. Tilsvarende analyserer en medisinsk forsker kreftdata for å forutsi hvilken medisin som skal forskrives til pasienten.
Kilder: - www.tutorialspoint.com
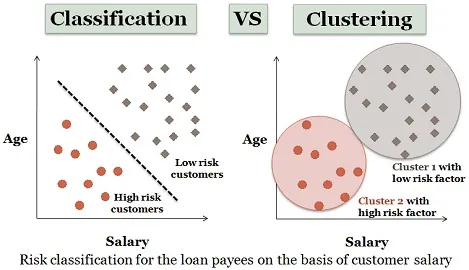
3. Clustering-analyse:
Clustering er nesten lik klassifisering, men i denne klyngene er laget avhengig av likhetene med dataelementer. Ulike klynger har forskjellige eller ikke-relaterte gjenstander. Det kalles også som datasegmentering ettersom det deler store datasett i klynger i henhold til likhetene.
Det er forskjellige klyngemetoder som brukes:
- Hierarkiske agglomerative metoder
- Nettbaserte metoder
- Partisjonsmetoder
- Modellbaserte metoder
- Tetthetsbaserte metoder
Lignende eksempel på lånesøkere kan også vurderes her. Det er noen forskjeller som er avbildet i figuren nedenfor.
https://bit.ly/2N6aZpP
4. Prediksjon:
Denne metoden brukes til å forutsi fremtiden basert på tidligere og nåværende trender eller datasett. Prediksjon brukes mest med kombinasjonen av andre data mining metoder, som klassifisering, mønster matching, trendanalyse og relasjon.
Hvis for eksempel salgssjefen i et supermarked ønsker å forutsi inntektsbeløpet som hver vare vil generere basert på tidligere salgsdata. Den modellerer kontinuerlig verdsatt funksjon som spår manglende numeriske dataverdier.

Kilder: - data-mining.philippe-fournier
Regresjonsanalyse er det beste valget å utføre prediksjon. Det kan brukes til å angi et forhold mellom uavhengige variabler og avhengige variabler.
5. Sekvensielle mønstre eller mønstersporing:
Denne data mining-metoden brukes til å identifisere mønstre som forekommer ofte over en viss periode.
For eksempel ser salgssjefen i klesbedrift at salget av jakker ser ut til å øke rett før vintersesongen, eller salget i bakeri øker i løpet av jula- eller nyttårsaften.
La oss se på et eksempel med en graf
Kilder: - data-mining.philippe-fournier-viger
6. avgjørelse trær:
Et beslutnings tre er en trestruktur (som navnet antyder), hvor
- Hver interne node representerer en test på attributtet.
- Gren avgir resultatet av testen.
- Terminalnoder holder klassetiketten.
- Den øverste noden er rotnoden som har det enkle spørsmålet som har to eller flere svar. Følgelig vokser treet og et flytskjema som struktur genereres.
Kilder: - www.tutorialride.com
I denne beslutningen klassifiserer tre myndigheter borgere under 18 år eller over 18 år. Dette vil hjelpe dem til å bestemme om en lisens må utstedes til en bestemt innbygger eller ikke.
7.Velgende analyse eller anomalieanalyse:
Denne data mining-metoden brukes til å identifisere dataelementene som ikke samsvarer med forventet mønster eller forventet oppførsel. Disse uventede dataelementene blir sett på som outliers eller støy. De er nyttige i mange domener som gjenkjenning av kredittkortsvindel, inntrengingsdeteksjon, feiloppdagelse osv. Dette kalles også for Outlier Mining .
La oss for eksempel anta at grafen nedenfor er plottet ved hjelp av noen datasett i databasen vår.
Så den beste passformlinjen tegnes. Punktene som ligger i nærheten av linjen viser forventet oppførsel mens punktet langt fra linjen er en Outlier.
Dette vil bidra til å oppdage anomaliene og iverksette mulige tiltak deretter.
https://bit.ly/2GrgjDP
8. Nevralt nettverk:
Denne dataminningsmetoden eller modellen er basert på biologiske nevrale nettverk. Det er en samling av nevroner som prosesseringsenheter med vektede forbindelser mellom dem. De brukes til å modellere forholdet mellom innganger og utganger. Den brukes til klassifisering, regresjonsanalyse, databehandling osv. Denne teknikken fungerer på tre søyler-
- Modell
- Læringsalgoritme (overvåket eller uten tilsyn)
- Aktiveringsfunksjon
Kilder: - www.saedsayad.com
Anbefalte artikler
Dette har vært en guide til Data Mining Methods Her har vi diskutert Hva er Data Mining og forskjellige typer Data Mining-metoden med eksemplet. Du kan også se på følgende artikler for å lære mer -
- Big Data Analytics-programvare
- Spørsmål om datastrukturintervju
- Viktige data gruvedriftsteknikker
- Data Mining Architecture