
Introduksjon til AWS Data Pipeline
Data vokser eksponentielt dag for dag og blir vanskelig å håndtere sammenlignet med fortiden. Vi trenger verktøy og tjenester for å administrere dataene våre effektivt og til en billigere pris. Det er der AWS Data Pipeline kommer i tankene. Det handler ikke bare om å lagre data, men du må analysere, behandle, transformere dataene til ønsket form på samme sted, alt dette kan oppnås med AWS Data Pipeline.
Behov for datapipeline
La oss prøve å forstå behovet for datapipeline med eksempelet:
Eksempel 1
Vi har et nettsted som viser bilder og gifs på grunnlag av brukersøk eller filtre. Vårt hovedfokus er å servere innhold. Det er visse mål å oppnå som er som følger:
- Forbedring av innholdslevering: Serverer det brukerne ønsker effektivt og raskt nok.
- Administrer applikasjonen effektivt: Lagring av brukerdata samt weblogger for senere analytiske formål.
- Forbedre virksomheten: Å bruke lagrede data og analyser tar beslutningen om å gjøre virksomheten bedre til en billigere pris.
Eksempel 2
Det er visse flaskehalser som skal tas vare på for å oppnå målene:
- Den enorme datamengden i forskjellige formater og forskjellige steder som gjør behandling, lagring og migrering av data kompleks.
Ulike datalagringskomponenter for forskjellige typer data:
- Mulige sanntidsdata for de registrerte brukerne: Dynamo DB .
- Web-serverlogger for potensielle brukere: Amazon S3 .
- Demografidata og påloggingsinformasjon: Amazon RDS.
- Sensordata og tredjeparts datasett: Amazon S3.
Solutions
- Gjennomførbar løsning: Vi ser at vi må håndtere forskjellige typer verktøy for å konvertere data fra ustrukturert til strukturert for analyse. Her må vi bruke forskjellige verktøy for å lagre data og igjen for å konvertere, analysere og lagre behandlede data. Ikke en kostnadseffektiv løsning.
- Optimal løsning: Bruk en datapipeline som håndterer behandling, visualisering og migrering. Datapipeline kan være nyttig i migrering av data fra forskjellige steder, også analysere data og behandle på samme sted på dine vegne.
Hva er AWS Data Pipeline?
AWS Data Pipeline er i utgangspunktet en webtjeneste som tilbys av Amazon som hjelper deg med å transformere, behandle og analysere dataene dine på en skalerbar og pålitelig måte, samt lagre behandlet data i S3, DynamoDb eller din lokale database.
- Med AWS Data Pipeline kan du enkelt få tilgang til data fra forskjellige kilder.
- Transformer og behandle disse dataene på skalaen.
- Effektiv overføring av resultater til andre tjenester som S3, DynamoDb-tabell eller lokale datalager.
Grunnleggende brukseksempel på datapipeline
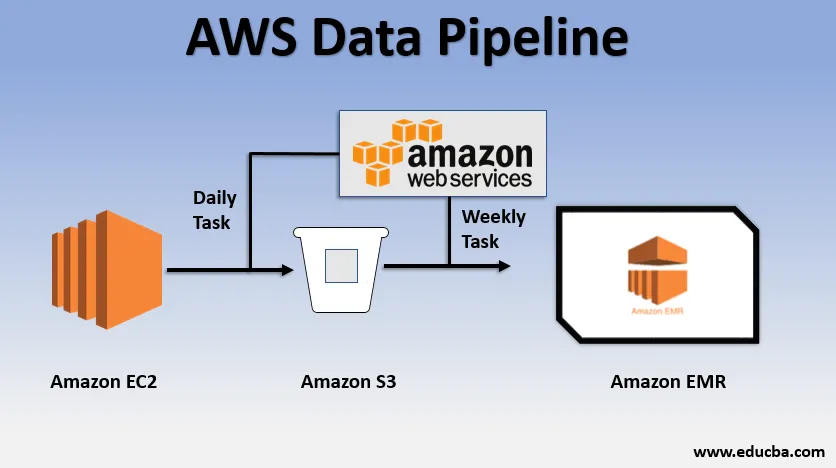
- Vi kan ha et nettsted distribuert over EC2 som genererer logger hver dag.
- En enkel daglig oppgave kan kopieres loggfiler fra E2 og oppnå dem til S3-bøtta.
- En ukentlig oppgave kan være å behandle dataene og starte dataanalyse over Amazon EMR for å generere ukentlige rapporter på grunnlag av all innsamlet data.
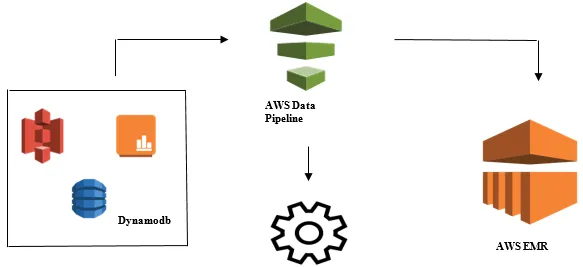
Lansering av dataanalyse med AWS Data Pipeline
- Innsamling av data fra forskjellige datakilder som - S3, Dynamodb, Lokale, sensordata, etc.
- Utføre transformasjon, prosessering og analyse på AWS EMR for å generere ukentlige rapporter.
- Ukesrapport lagret i Redshift, S3 eller lokal database.
Fordelene med AWS Data Pipeline
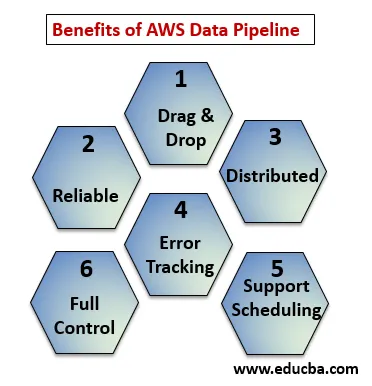
Under punktene forklarer fordelene med AWS Data Pipeline:
- Dra og slipp-konsoll som er lett å forstå og bruke.
- Distribuert og pålitelig infrastruktur: Datarørledninger kjører på skalerbare tjenester og er pålitelige hvis noen feil eller oppgave mislykkes, det kan stilles inn for å prøve på nytt.
- Støtter planlegging og feilsøking: Du kan planlegge oppgavene dine og spore dem hva som ble mislykket og suksess.
- Distribuert: Kan kjøres parallelt på flere maskiner eller på en lineær måte.
- Full kontroll over beregningsressurser som EC2, EMR-klynger.
AWS Data Pipeline Components
Nedenfor er komponentene i AWS Data Pipeline:
1. Definisjon av rørledning
Konverter virksomhetslogikken til AWS Data Pipeline.
- Datanoder : Inneholder navn, beliggenhet, format for datakilde det kan være (S3, dynamodb, lokal)
- Aktiviteter : Flytt, transformer eller utfør spørsmål på dataene dine.
- Planlegg : Planlegg daglige eller ukentlige aktiviteter.
- Forutsetning : Forhold som for å starte planlegger, sjekk datatilgjengeligheten ved kilden.
- Ressurser : Beregn ressurser EC2, EMR.
- Handlinger : Oppdatering om datapipeline, sending av varsler, triggeralarm.
2. Rørledninger
Her planlegger og kjører du oppgavene for å utføre definerte aktiviteter.
- Pipeline C omponents: Rørledningskomponenter er de samme som komponentene i rørledningsdefinisjonen.
- Forekomster: Mens AWS kjører oppgaver, kompilerer alle komponentene for å lage visse handlingsbare forekomster. Slike forekomster har all informasjon om spesifikke oppgaver.
- Forsøk: Vi har allerede diskutert hvor pålitelig datapipeline er med sine prøvemekanismer. Her angir du hvor mange ganger du vil prøve på nytt, i tilfelle den mislykkes.
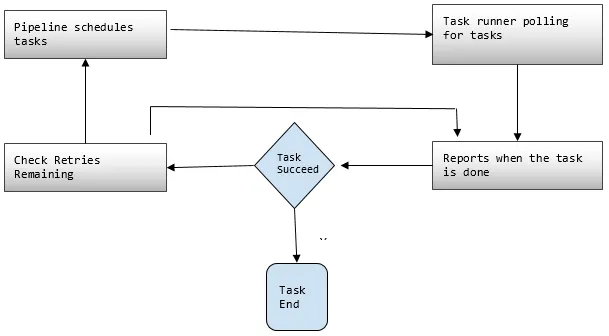
3. Oppgaveløper
Ber eller avstemmer om oppgaver fra AWS Data Pipeline og utfører deretter oppgavene.
AWS Data Pipeline Prising
Under punktene forklarer AWS Data-rørledningspriser:
1. Gratis nivå
Du kan komme i gang med AWS Data Pipeline gratis som en del av AWSs gratis bruksnivå. Nye registrerte kunder får hver måned noen gratis fordeler i ett år:
- 3 Forutsetninger for lavfrekvens som kjører på AWS uten lading.
- 5 Aktiviteter med lav frekvens som kjører på AWS uten lading.
2. Lav frekvens
Lav frekvens er ment å løpe en gang på en dag eller mindre. Datapipeline følger den samme faktureringsstrategien som andre AWS webtjenester, dvs. fakturert for din bruk. Det blir fakturert hvor ofte dine oppgaver, aktiviteter og forutsetninger kjøres hver dag og hvor de kjører (AWS eller på stedet). Høyfrekvente aktiviteter er planlagt å kjøre mer enn en gang om dagen.
Eksempel: Vi kan planlegge en aktivitet som skal kjøres hver time og behandle nettstedets logger, eller det kan være hver 12. time. Mens lavfrekvente aktiviteter er de som kjøres en gang om dagen eller mindre hvis forutsetningene ikke er oppfylt. Inaktive rørledninger har enten inaktive, ventende og ferdige tilstander.
3. Prisfastsettelse av AWS-datarørledning vist Regionmessig
Region nr. 1: US East (N.Virginia), US West (Oregon), Asia Pacific (Sydney), EU (Ireland)
| Høy frekvens | Lav frekvens | |
| Aktiviteter eller forutsetninger som løper over AWS | $ 1, 00 per måned | 0, 06 dollar per måned |
| Aktiviteter eller forutsetninger som kjører på stedet | $ 2, 50 per måned | $ 1, 50 per måned |
| Inaktive rørledninger: $ 1, 00 per måned |
Region nr. 2: Asia Pacific (Tokyo)
| Høy frekvens | Lav frekvens | |
| Aktiviteter eller forutsetninger som løper over AWS | 0, 9524 dollar per måned | $ 0, 5715 per måned |
| Aktiviteter eller forutsetninger som kjører på stedet | 2, 381 dollar per måned | 1, 4286 dollar per måned |
| Inaktive rørledninger: $ 0.9524 per måned |
Rørledningen som en daglig jobb, dvs. en lavfrekvensaktivitet på AWS for å flytte data fra DynamoDB-tabellen til Amazon S3, vil koste $ 0, 60 per måned. Hvis vi legger til EC2 for å produsere en rapport basert på Amazon S3-data, vil den totale rørledningskostnaden være $ 1, 20 per måned. Hvis vi kjører denne aktiviteten hver sjette time, vil det koste $ 2, 00 per måned, for da ville det være en høyfrekvent aktivitet.
Konklusjon
AWS Data Pipeline er en veldig praktisk løsning for å håndtere eksponentielt voksende data til en billigere pris. Den er veldig pålitelig og skalerbar i henhold til bruken din. AWS Data Pipeline er et veldig godt valg for å nå alle våre forretningsmessige mål for ethvert forretningsbehov der det omhandler en stor datamengde.
Anbefalte artikler
Dette er en guide til AWS Data Pipeline. Her diskuterer vi behovene til datapipeline, hva er AWS data pipeline, dets komponent og prisdetaljer. Du kan også gå gjennom andre relaterte artikler for å lære mer -
- AWS EBS
- AWS-databaser
- Hva er AWS EC2?
- Fordeler med datavisualisering
- Topp 7 konkurrenter av AWS med funksjoner
- Lær listen over Amazon Web Services-funksjoner