
Lineær regresjon i Excel (innholdsfortegnelse)
- Introduksjon til lineær regresjon i Excel
- Metoder for bruk av lineær regresjon i Excel
Introduksjon til lineær regresjon i Excel
Lineær regresjon er en statistisk teknikk / metode som brukes for å studere forholdet mellom to kontinuerlige kvantitative variabler. I denne teknikken brukes uavhengige variabler for å forutsi verdien av en avhengig variabel. Hvis det bare er en uavhengig variabel, er det en enkel lineær regresjon, og hvis et antall uavhengige variabler er mer enn en, så er det multippel lineær regresjon. Lineære regresjonsmodeller har et forhold mellom avhengige og uavhengige variabler ved å tilpasse en lineær ligning til de observerte dataene. Lineær refererer til det faktum at vi bruker en linje som passer til våre data. De avhengige variablene som brukes i regresjonsanalyse kalles også respons eller forutsagte variabler, og uavhengige variabler kalles også forklaringsvariabler eller prediktorer.
En lineær regresjonslinje har en ligning av typen: Y = a + bX;
Hvor:
- X er den forklarende variabelen,
- Y er den avhengige variabelen,
- b er skråningen,
- a er y-avskjæring (dvs. verdi av y når x = 0).
Minstekvadratmetoden brukes vanligvis i lineær regresjon som beregner den beste passformlinjen for observerte data ved å minimere summen av kvadratene for avvik for datapunkter fra linjen.
Metoder for bruk av lineær regresjon i Excel
Dette eksemplet lærer deg metodene for å utføre Lineær regresjonsanalyse i Excel. La oss se på noen få metoder.
Du kan laste ned denne Linear Regression Excel Mal her - Linear Regression Excel TemplateMetode nr. 1 - Spredningskart med en trendline
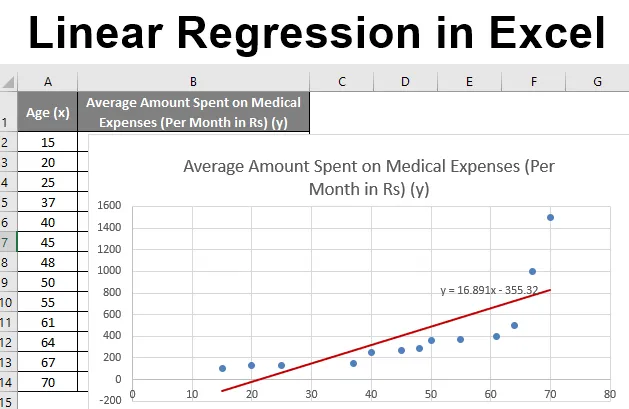
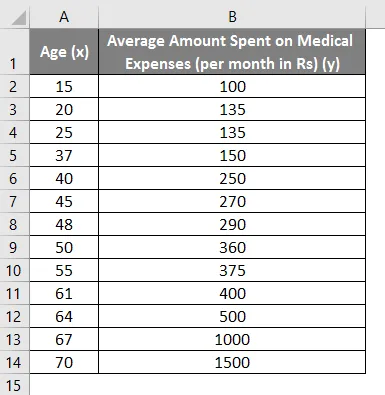
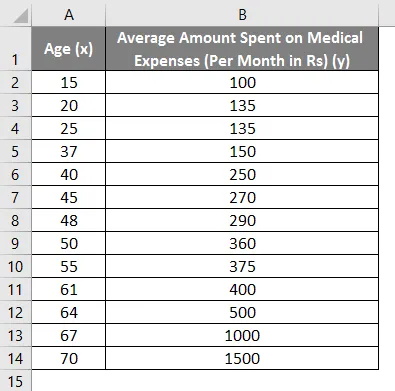
La oss si at vi har et datasett med noen individer med deres alder, biomasseindeks (BMI) og beløpet de bruker på medisinske utgifter i løpet av en måned. Nå med en innsikt i individenes egenskaper som alder og BMI, ønsker vi å finne hvordan disse variablene påvirker de medisinske utgiftene, og bruker derfor disse til å utføre regresjon og estimere / forutsi de gjennomsnittlige medisinske utgiftene for noen spesifikke individer. La oss først se hvordan bare alder påvirker medisinske utgifter. La oss se datasettet:
Beløp på medisinske utgifter = b * alder + a
- Velg de to kolonnene i datasettet (x og y), inkludert overskrifter.
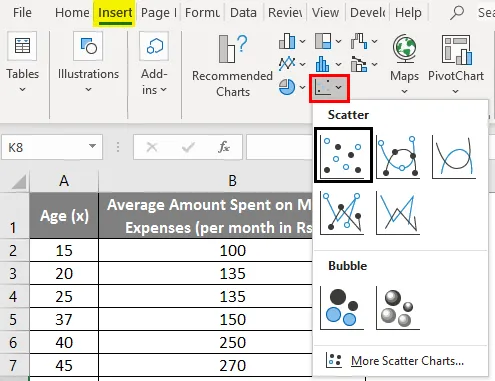
- Klikk på "Sett inn" og utvid rullegardinmenyen for "Scatter Chart" og velg "Scatter" miniatyrbilde (første)
- Nå vises et scatter-plot, og vi ville tegne regresjonslinjen for dette. For å gjøre dette, høyreklikk på hvilket som helst datapunkt og velg "Legg til trendlinje"
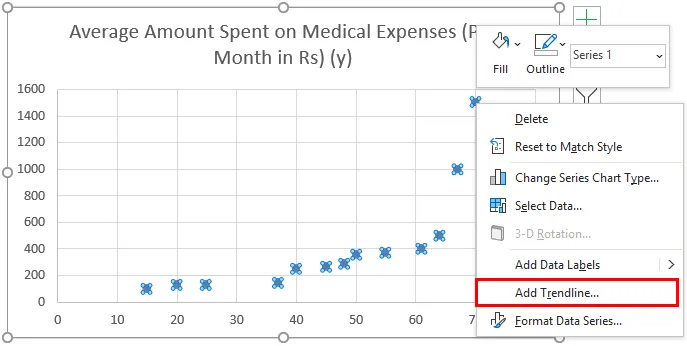
- Nå i "Format Trendline" -rute til høyre, velg "Linear Trendline" og "Display Equation on Chart".
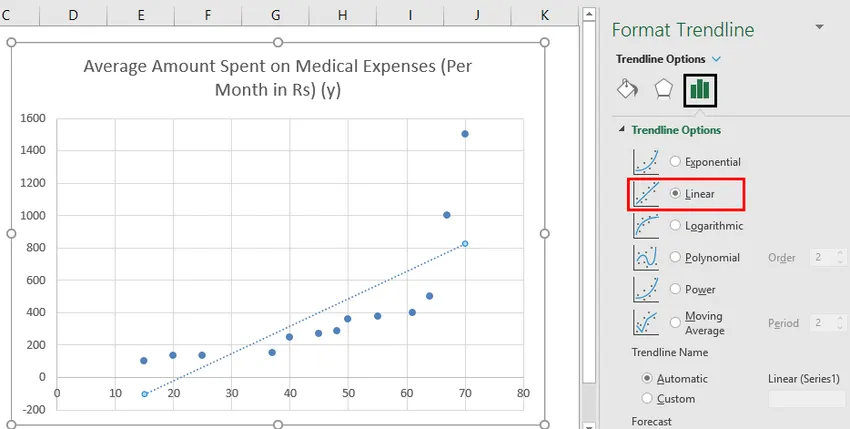
- Velg 'Vis ligning på kartet'.
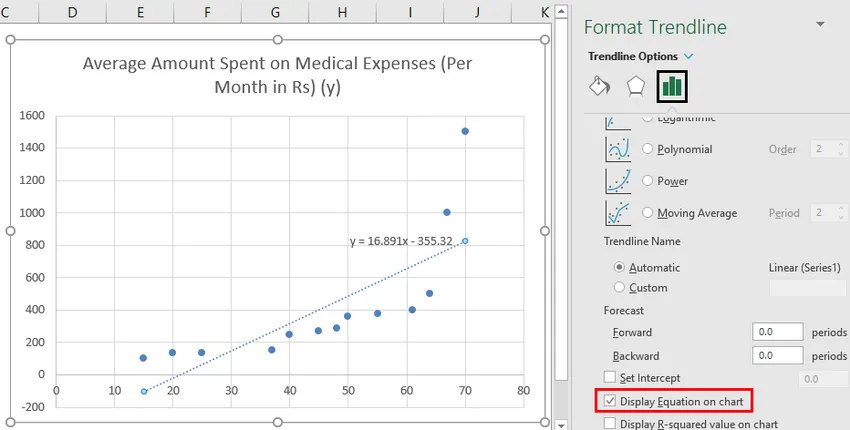
Vi kan improvisere diagrammet i henhold til kravene våre, som å legge til aksetitler, endre skala, farge og linjetype.
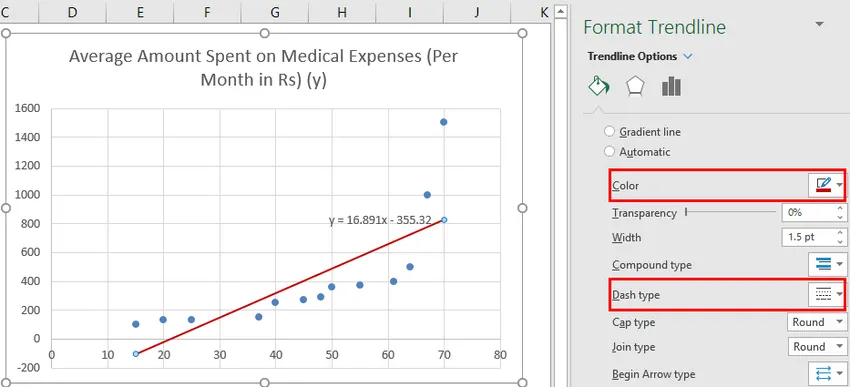
Etter å ha improvisert diagrammet er dette resultatet vi får.

Metode nr. 2 - AnalyseverktøyPak tilleggsmetode
AnalyseverktøyPak er noen ganger ikke aktivert som standard, og vi må gjøre det manuelt. Å gjøre slik:
- Klikk på 'Fil' -menyen.
Etter det klikker du på 'Alternativer'.
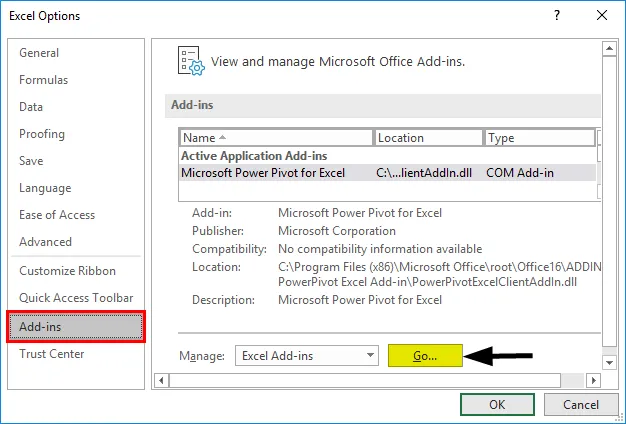
- Velg "Excel-tillegg" i "Administrer" -boksen, og klikk på "Gå"
- Velg 'AnalyseverktøyPak' -> 'OK'
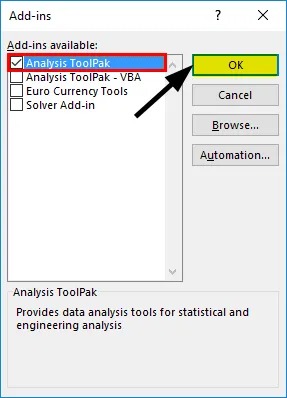
Dette vil legge til "Data Analyse" -verktøy til "Data" -fanen. Nå kjører vi regresjonsanalysen:
- Klikk på 'Dataanalyse' i fanen 'Data'
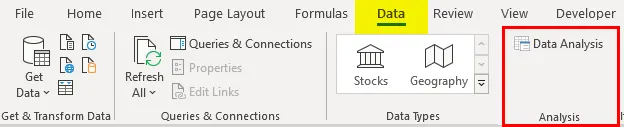
- Velg 'Regresjon' -> 'OK'
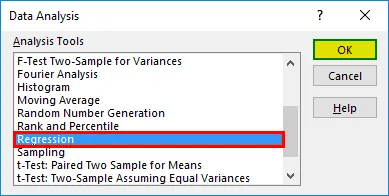
- En regresjonsdialogboks vises. Velg Input Y-område og Input X-område (henholdsvis medisinske utgifter og alder). I tilfelle multippel lineær regresjon, kan vi velge flere kolonner med uavhengige variabler (som om vi ønsker å se effekten av BMI også på medisinske utgifter).
- Merk av for "Etiketter" for å inkludere overskrifter.
- Velg ønsket "output" -alternativ.
- Merk av for "rester" og klikk "OK".
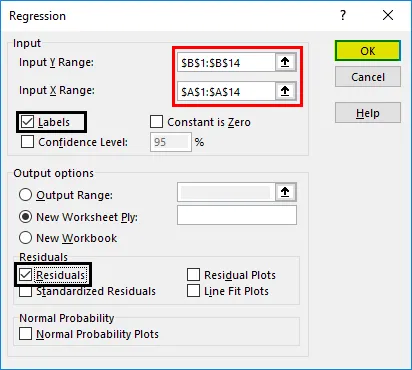
Nå blir vår regresjonsanalyseproduksjon opprettet i et nytt regneark med angivelse av regresjonsstatistikk, ANOVA, rester og koeffisientene.
Fortolkning:
- Regresjonsstatistikk forteller hvor godt regresjonsligningen passer til dataene:
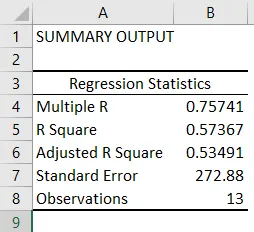
- Multiple R er korrelasjonskoeffisienten som måler styrken i den lineære sammenhengen mellom to variabler. Den ligger mellom -1 og 1, og dens absolutte verdi skildrer relasjonsstyrken med en stor verdi som indikerer sterkere forhold, lav verdi som indikerer negativ og null verdi som indikerer ingen relasjon.
- R Square er bestemmelseskoeffisienten som brukes som en indikator på passformens godhet. Den ligger mellom 0 og 1, med en verdi nær 1 som indikerer at modellen passer godt. I dette tilfellet er 0, 57 = 57% av y-verdiene forklart med x-verdiene.
- Justert R Square er R Square justert for antall prediktorer i tilfelle multippel lineær regresjon.
- Standard Error viser presisjonen for regresjonsanalyse.
- Observasjoner viser antall modellobservasjoner.
- Anova forteller om variabilitetsnivået innen regresjonsmodellen.

Dette brukes vanligvis ikke for enkel lineær regresjon. Imidlertid indikerer 'Betydning F-verdiene' hvor pålitelige resultatene våre er, med en verdi større enn 0, 05 som antyder å velge en annen prediktor.
- Koeffisienter er den viktigste delen som brukes til å bygge regresjonsligning.

Så vår regresjonsligning ville være: y = 16.891 x - 355.32. Dette er det samme som gjort med metode 1 (spredningskart med en trendline).
Hvis vi nå ønsker å forutsi gjennomsnittlige medisinske utgifter når alderen er 72:
Så y = 16, 891 * 72 -355, 32 = 860, 832
Så på denne måten kan vi forutsi verdier av y for alle andre verdier på x.
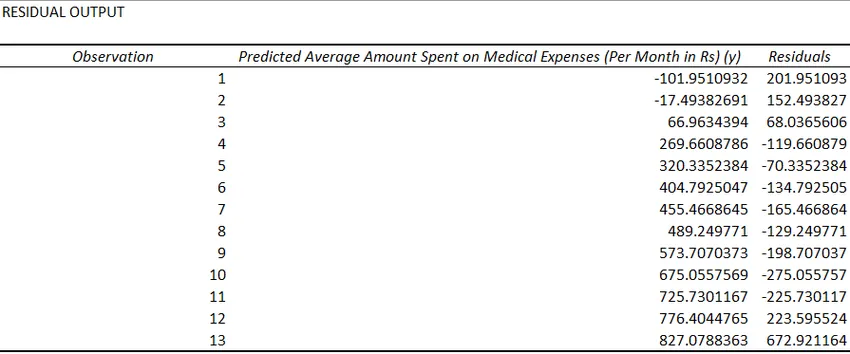
- Restpersoner indikerer forskjellen mellom faktiske og forutsagte verdier.
Den siste metoden for regresjon er ikke så ofte brukt og krever statistiske funksjoner som skråning (), avskjæring (), korrel (), etc. for å utføre regresjonsanalyse.
Ting å huske på om lineær regresjon i Excel
- Regresjonsanalyse brukes vanligvis for å se om det er en statistisk signifikant sammenheng mellom to sett med variabler.
- Den brukes til å forutsi verdien av den avhengige variabelen basert på verdier av en eller flere uavhengige variabler.
- Hver gang vi ønsker å tilpasse en lineær regresjonsmodell til en datagruppe, så bør dataområdet følges nøye som om vi bruker en regresjonsligning for å forutsi noen verdi utenfor dette området (ekstrapolering), så kan det føre til gale resultater.
Anbefalte artikler
Dette er en guide til Lineær regresjon i Excel. Her diskuterer vi hvordan du gjør Lineær regresjon i Excel sammen med praktiske eksempler og nedlastbar Excel-mal. Du kan også gå gjennom andre foreslåtte artikler -
- Hvordan forberede lønn i Excel?
- Bruk av MAX-formler i Excel
- Veiledninger om cellehenvisninger i Excel
- Opprette regresjonsanalyse i Excel
- Lineær programmering i Excel