

Introduksjon til AWS EMR
AWS EMR gir mange funksjoner som gjør ting enklere for oss, noen av teknologiene er:
- Amazon EC2
- Amazon RDS
- Amazon S3
- Amazon CloudFront
- Amazon Auto Scaling
- Amazon Lambda
- Amazon Redshift
- Amazon Elastic MapReduce (EMR)
En av de viktigste tjenestene som tilbys av AWS EMR og vi skal takle er Amazon EMR.
EMR ofte kalt Elastic Map Reduce kommer med en enkel og tilgjengelig måte å håndtere behandlingen av større biter av data. Se for deg et big data-scenario der vi har en enorm mengde data og vi utfører et sett med operasjoner over dem, si at en Map-Reduce-jobb kjører, en av de viktigste problemene som Bigdata-applikasjonen står overfor er innstilling av programmet, vi synes ofte det er vanskelig å finjustere programmet vårt på en slik måte at all ressurs som er tildelt blir brukt riktig. På grunn av denne innstillingsfaktoren over øker tiden det tar å behandle gradvis. Elastic Map Reduce the service by Amazon, er en webtjeneste som gir et rammeverk som administrerer alle disse nødvendige funksjonene som er nødvendige for Big databehandling på en kostnadseffektiv, rask og sikker måte. Fra oppretting av klynger til datadistribusjon over forskjellige tilfeller, alle disse tingene er enkelt å administrere under Amazon EMR. Tjenestene her er on-demand betyr at vi kan kontrollere tallene basert på dataene vi har som gjør om det er kostnadseffektivt og skalerbart.
Årsaker til bruk av AWS EMR
Så hvorfor bruke AMR hva gjør det bedre fra andre. Vi møter ofte et veldig grunnleggende problem der vi ikke klarer å allokere alle ressursene som er tilgjengelige over klyngen til noen applikasjoner, hvor AMAZON EMR tar seg av disse problemene og basert på datastørrelse og etterspørselen etter applikasjon som den fordeler den nødvendige ressursen. Ved å være elastisk i naturen kan vi også endre det tilsvarende. EMR har enorm applikasjonsstøtte det være seg Hadoop, Spark, HBase som gjør det enklere for databehandling. Den støtter forskjellige ETL-operasjoner raskt og kostnadseffektivt. Det kan også brukes over til MLIB i Spark. Vi kan utføre forskjellige maskinlæringsalgoritmer inni den. Det være seg batchdata eller sanntidsstrømming av data EMR er i stand til å organisere og behandle begge typer data.
Arbeid med AWS EMR
La oss nå se dette diagrammet av Amazon EMR-klyngen, og vil prøve å forstå hvordan det faktisk fungerer:
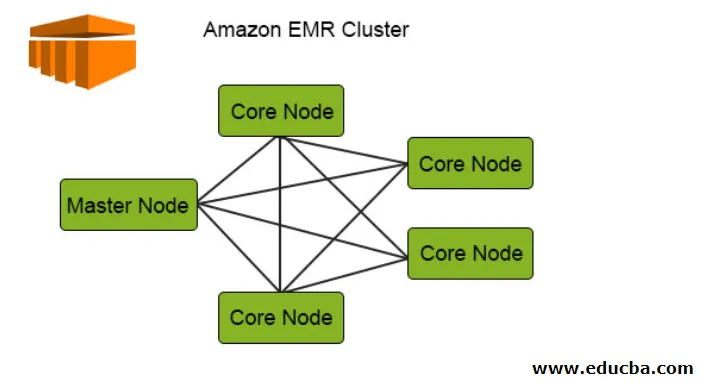
Følgende diagram viser klyngedistribusjonen til EMR. La oss sjekke det i detalj:
1. Klyngene er den sentrale komponenten i Amazon EMR-arkitekturen. De er en samling av EC2-forekomster kalt noder. Hver node har sine spesifikke roller i klyngen betegnet som nodetype, og basert på deres roller kan vi klassifisere dem i tre typer:
- Master Node
- Kjerneknute
- Oppgaveknute
2. Masternoden, som navnet antyder, er masteren som er ansvarlig for å håndtere klyngen, kjøre komponentene og distribusjonen av data over nodene for behandling. Det holder bare spor om alt er riktig styrt og kjører fint og fungerer på i tilfelle feil.
3. Core Node har ansvaret for å kjøre oppgaven og lagre dataene i HDFS i klyngen. Alle behandlingsdelene håndteres av kjerneknuten, og dataene etter at behandlingen blir satt til ønsket HDFS-sted.
4. Oppgavenoden som er valgfri har bare jobben for å kjøre oppgaven, dette lagrer ikke dataene i HDFS.
5. Hver gang vi har sendt inn en jobb, har vi flere metoder for å velge hvordan arbeidene skal fullføres. Å være det fra terminering av klyngen etter endt jobb til en langvarig klynge som bruker EMR-konsoll og CLI for å sende inn trinn, vi har alle privilegium å gjøre det.
6. Vi kan direkte kjøre jobben på EMR ved å koble den til hovednoden gjennom grensesnittene og verktøyene som er tilgjengelige som kjører jobber direkte i klyngen.
7. Vi kan også kjøre dataene våre i forskjellige trinn ved hjelp av EMR, alt vi trenger å gjøre er å sende inn ett eller flere bestilte trinn i EMR-klyngen. Dataene lagres som en fil og behandles på en sekvensiell måte. Starter den fra "Venter tilstand til fullført tilstand" kan vi spore prosesseringstrinnene og finne feilene også ved at det er fra 'Failed to Canceled'. Alle disse trinnene kan lett spores tilbake til dette.
8. Når hele forekomsten er avsluttet, oppnås fullført tilstand for klyngen.
Arkitektur for AWS EMR
Arkitekturen til EMR introduserer seg selv fra lagringsdelen til applikasjonsdelen.
- Det aller første laget kommer med lagringslaget som inkluderer forskjellige filsystemer som brukes i klyngen vår. Det være seg fra HDFS til EMRFS til lokalt filsystem. Disse brukes til datalagring over hele applikasjonen. Bufring av mellomresultatene under MapReduce-prosessering kan oppnås ved hjelp av disse teknologiene som følger med EMR.
- Det andre laget kommer med ressursstyring for klyngen, dette laget er ansvarlig for ressursstyring for klyngene og nodene over applikasjonen. Dette hjelper i utgangspunktet som administrasjonsverktøy som hjelper deg med å fordele data jevnt over klynge og korrekt administrasjon. Standard ressursstyringsverktøyet som EMR bruker er YARN som ble introdusert i Apache Hadoop 2.0. Den administrerer sentralt ressursene for flere databehandlingsrammer. Den tar vare på all informasjonen som er nødvendig for at klyngen skal være i god drift, og være den fra nodehelse til ressursfordeling med minnestyring.
- Det tredje laget kommer med databehandlingsrammeverket, dette laget er ansvarlig for analysen og behandlingen av data. det er mange rammer støttet av EMR som spiller en viktig rolle i parallell og effektiv databehandling. Noen av rammene den støtter og vi er klar over er APACHE HADOOP, SPARK, SPARK STREAMING, etc.
- Det fjerde laget kommer med applikasjonen og programmer som HIVE, PIG, streaming-bibliotek, ML-algoritmer som er nyttige for behandling og administrasjon av store datasett.
Fordeler med AWS EMR
La oss nå sjekke noen av fordelene ved å bruke EMR:
- Høy hastighet: Siden alle ressursene blir brukt riktig, er behandlingstiden for spørringen relativt raskere enn de andre databehandlingsverktøyene har et mye tydelig bilde.
- Bulk databehandling: Vær større datastørrelsen EMR har muligheten til å behandle enorme datamengder på god tid.
- Minimal datatap: Siden data distribueres over klyngen og behandles parallelt over nettverket, er det en minimal sjanse for tap av data og vel, er nøyaktighetsgraden for de behandlede dataene bedre.
- Kostnadseffektivt: Å være kostnadseffektivt er det billigere enn noe annet alternativ tilgjengelig som gjør det sterkt over bruken av industrien. Siden prisene er mindre, kan vi få plass til store datamengder og kan behandle dem innenfor budsjettet.
- AWS Integrated: Det er integrert med alle tjenestene til AWS som gir enkel tilgjengelighet under et tak, slik at sikkerhet, lagring, nettverk alt er integrert på ett sted.
- Sikkerhet: Det kommer med en utrolig sikkerhetsgruppe for å kontrollere inn- og utgående trafikk, og bruk av IAM-roller gjør det sikrere da det kommer opp med forskjellige tillatelser som gjør dataene sikre.
- Overvåking og distribusjon: vi har riktige overvåkningsverktøy for alle applikasjonene som kjører over EMR-klynger, noe som gjør det gjennomsiktig og enkelt å analysere, og det kommer også med en automatisk distribusjonsfunksjon der applikasjonen konfigureres og distribueres automatisk.
Det er mange flere fordeler med å ha EMR som en bedre valg av annen klyngedatormetode.
AWS EMR Prising
EMR kommer med en fantastisk prisnotering som tiltrekker utviklere eller markedet mot den. Siden det kommer med en prisfunksjon på forespørsel, kan vi bruke den litt over en times basis og antall noder i klyngen vår. Vi kan betale for en rate per sekund for hvert sekund vi bruker med ett minutt som minimum. Vi kan også velge forekomster som skal brukes som Reserved Instances eller Spot Instances, der stedet koster mye.
Vi kan beregne den totale regningen over en enkel månedlig kalkulator fra lenken nedenfor: -
https://calculator.s3.amazonaws.com/index.html#s=EMR
For mer informasjon om de nøyaktige prisopplysningene, kan du se dokumentet nedenfor av Amazon: -
https://aws.amazon.com/emr/pricing/
Konklusjon
Fra artikkelen ovenfor så vi hvordan EMR kan brukes til rettferdig behandling av big data med alle ressursene som brukes konvensjonelt.
Å ha EMR løser vårt grunnleggende problem med databehandling og reduserer mye behandlingstiden med et godt antall, fordi det er kostnadseffektivt er det enkelt og praktisk å bruke.
Anbefalt artikkel
Dette har vært en guide til AWS EMR. Her diskuterer vi en introduksjon til AWS EMR langs Working and the Architecture så vel som fordelene. Du kan også gå gjennom andre foreslåtte artikler for å lære mer -
- AWS Alternativer
- AWS-kommandoer
- AWS Services
- AWS intervjuspørsmål
- AWS Storage Services
- Topp 7 konkurrenter av AWS
- Liste over Amazon Web Services-funksjoner