

Hva er Kafka?
For å forstå Kafka er det bedre å forstå hva 'Streambehandling' -teknologi er. 'Strømbehandling er en teknologi som brukeren kan spørre om en kontinuerlig datastrøm i en mikrotidsramme for å bedre forstå underliggende forhold som er ansvarlige.
Et sanntids scenario - tenk om temperatursensoren din sender data som du kan spørre og motta et varsel etter at et frysepunkt er mottatt. Denne datasøket kan gjøres i mikrosekunder.
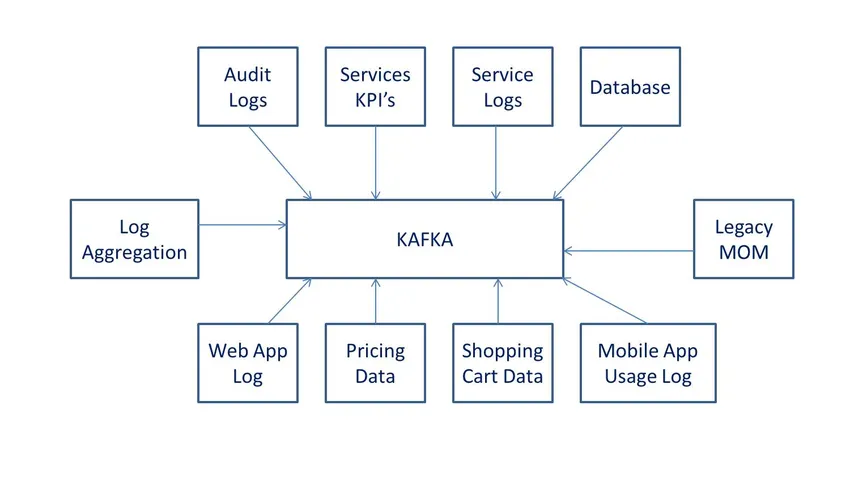
definisjoner
i følge Wiki er det programvare for databehandler med åpen kildekode. Den ble utviklet av LinkedIn og senere gitt til Apache-programvare.
Forstå Kafka
Veksten eksploderer eksponentielt. La oss se noen fakta og statistikk for bedre å understreke vår tanke. Det nyter godt av mer enn en tredjedel av Fortune 500 over hele kloden. Denne distribusjonen deles av reisevirksomheter, telekomgiganter, banker og flere andre. LinkedIn, Microsoft og Netflix behandler fire kommameldinger om dagen med Kafka (nesten tilsvarer 1.000.000.000.000).
Det brukes til sanntids datastrømmer, til å samle inn big data eller for å gjøre sanntidsanalyse (eller begge deler). Kafka brukes med mikroservices i minnet for å gi holdbarhet, og den kan brukes til å mate hendelser til CEP (komplekse hendelsesstrømningssystemer) og IoT / IFTTT-automatiseringssystemer.
Hvordan fungerer Kafka så enkelt?
Drevet av enkelhet ville være den rette måten å definere ytelsen. Det er lett å finne ut hvordan Kafka fungerer så enkelt fra oppsett og bruk. Denne økte ytelsen i atferd er dedikert til stabiliteten, den gir pålitelig holdbarhet, med sin fleksible innebygde evne til å publisere eller abonnere eller vedlikeholde køen. Dette er veldig viktig å ha hvis du trenger å håndtere N - antall klientgrupper, hvis du må vise en robust replikering i markedet, med det formål å gi kundene dine en jevn tilnærming (dvs. Kafka emnepartisjon). En avgjørende oppførsel hos Kafka som skiller den fra sine konkurrenter er kompatibiliteten til systemer med datastrømmer - dens prosess og gjør det mulig for disse systemene for å samle, transformere og laste andre butikker for bekvemmelighetsarbeid. "Alle de ovennevnte fakta ville ikke vært mulig hvis Kafka var treg". Den eksepsjonelle ytelsen gjør dette mulig.
Med ytterligere tillegg til at Kafka kan fungere, må vi gå til “OS Level”. La oss finne ut hvordan ting fungerer for Kafka på OS-nivå -
- Den er avhengig av OS-kjerner for å flytte data raskere og fungerer på prinsippet om nullkopi.
- Det gjør det mulig å samle dataoppføringer i biter som kan sees fra filsystem (aka Kafka-emnelogg) til forbrukere.
- Fasiliteten til å batchdata gir en effektiv datakomprimering med reduksjon av I / O-latenstid.
- Den har muligheten til å skalere horisontalt via avskjerming. Det kan skjære en tittellogg inn i hundrevis av partisjoner til tusenvis. Dette gjør at den enkelt kan håndtere den enorme arbeidsmengden.
Hva kan du gjøre med Kafka?
Hvis selskapet ditt spiller med enorme datasett med jevne mellomrom, trenger du Kafka. Det er en lang liste over selskaper som bruker den.
- LinkedIn bruker for å spore data og operasjonelle beregninger.
- Twitter for å tilby infrastruktur for prosessering av strømmer.
Det er en lang liste over selskaper fra Uber til Spotify og Goldman Sachs til Cisco.
Fordeler
- Høy gjennomstrømning: Den kan lett håndtere et stort datamengde når generering med høy hastighet er en eksepsjonell fordel til fordel for Kafka. Denne applikasjonen mangler enorm maskinvare. Med kapasitet til å støtte gjennomstrømning av meldinger med en frekvens på tusenvis av meldinger per sekund.
- Lav latens : Lav latenstid som håndterer denne generasjonen av høyt volum.
- Feil-toleranse: Denne funksjonen er veldig nyttig, den har en iboende evne til å begrenses av noden innebygd i en klynge.
- Holdbar: den er veldig holdbar i driften og er derfor grunnen til at mange MNC foretrekker å bruke Kafka. Når vi snakker om holdbarhet i operasjoner, kan ikke meldingene gå tapt på lang sikt.
Nødvendige ferdigheter
Det er ingen spesielle krav for å være profesjonell fra Kafka. Men vi har understreket noen strømmer og fagpersoner -
- Utviklere som villig ønsker å gjøre en karriere i Big Data-strømmen og ønsker å akselerere karrieren der.
- Testing av profesjonelle har et godt omfang i Kafka når det gjelder kø- og meldingssystemer
- Arkitekter - siden alt trenger noen rammer og denne rammen kan oppdateres fra tid til annen. Big Data-arkitekter ville finne Kafka som en god karriereinvestering.
- Prosjektleder er nødvendig hvis den profesjonelle ovenfor er der for bedre styring av ressursene. Så høyere stillinger er også tilgjengelig for lederne innen Kafka.
Hvorfor bruke Kafka?
For å spore data og manipulere dem i henhold til forretningsbehovet, foretrekkes Kafka over hele verden. Det gir muligheten til å streame data i sanntid med sanntidsanalyse. Det er raskt, skalerbart og holdbart og designet som feiltoleranse. Det er flere brukssaker til stede på nettet der du kan se hvorfor JMS, RabbitMQ og AMQP ikke en gang anses å jobbe med ettersom behovet er å betjene stort volum og lydhørhet.
Den har høy gjennomstrømning, pålitelig oppsett med replikasjonsegenskaper som gjør det til et foretrukket valg å jobbe med IoT-sensorer.
Kompatibilitet er en annen grunn til å bruke den og gjorde den akseptabel over hele verden. Det kan enkelt konfigureres til å arbeide med applikasjonen nedenfor. Denne kombinasjonen er veldig viktig for mange selskaper for å vokse virksomhet og overleve (da det sparer tid og penger).
- Flume
- Gniststrømming
- HBase
- Gnist for sanntid svelging, behandling og analyse av data.
- Det er vant til å mate Hadoop BigData
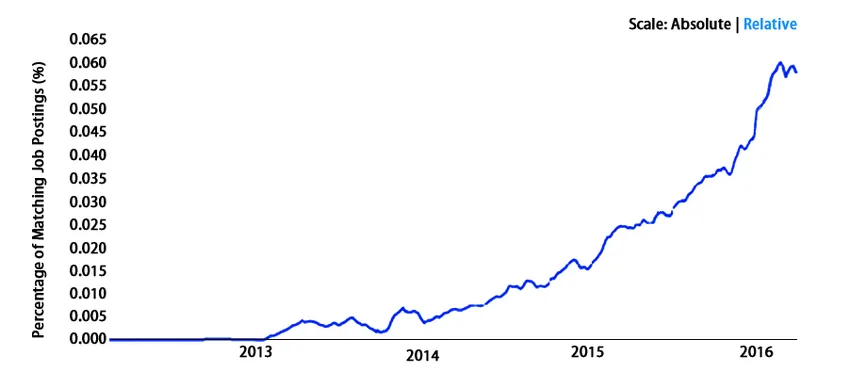
omfang
Det går bra over hele kloden. Vel, vi sier ikke dette statistikk. La oss se -
Lønnsstatistikk for Kafka-profesjonelle - PayScale
- Software Engineer - 109.825 dollar
- Data Engineer - 109.580 dollar
- Utviklere - 81 182 dollar
- Senior Data Engineer - $ 127, 836
Konklusjon
For tiden har Kafka blitt de-facto-standarden når det kommer til sanntids dataanalyse med høyest presisjon i mikrosekunder. Vi har presentert vår innsikt når det gjelder data og detaljer til støtte for Kafka-teknologier. Det er flere store selskaper som utnytter data daglig, og ved å gjøre dette trenger de fagfolk for å utnytte disse enorme datasettene. Med Kafka kan man være trygg på å lede sin karriere i en BigData-analyse
Anbefalte artikler
Dette har vært en guide til Hva er Kafka. Her diskuterte vi arbeidet, omfanget, karriereveksten og fordelene ved Kafka. Du kan også gå gjennom andre foreslåtte artikler for å lære mer -
- Hva er Apache?
- Hva er Big data og Hadoop?
- Hva er Azure?
- Hva er Big Data Technology?
- Kafka vs Spark | Topp 5 forskjeller
- Oversikt og topp applikasjoner av Kafka
- Kafka vs Kinesis | 5 Forskjeller med infografikk