

Slik installerer du Apache
Før vi går inn på hvordan du installerer Apache-delen, vil vi først ha en generell oversikt over Apache og hvordan den brukes i data science.
Hva er Apache?

Apache Web Server er en HTTP-server som presenterer nettsteder for besøkende som kommer til serveren din. Så hvis du vil distribuere et nettsted for en bedrift eller organisasjon, vil du sannsynligvis bruke Apache til det.
Det er andre HTTP-servere der ute, for eksempel IIS, men Apache er standarden som folk flest bruker, enten de er på Linux, Windows eller Mac. Apache er standard som folk flest går til fordi det er velkjent, det er veldig pålitelig og det er gratis.
En ting å innse med Apache er imidlertid at ettersom det er en HTTP-server, så hvis du installerer dette på Linux eller Windows eller Mac, vil det bare gjøre å presentere statiske nettsteder for besøkende som kommer til serveren din. Derfor, hvis du koder ut et HTML-nettsted uten andre programmeringsspråk enn JavaScript, kan du bruke det med bare en Apache-server. Du kan koble alle kodene til Apache-serveren og presentere dem for besøkende.
Hvordan brukte Apache i Data Science?
Data Science er det mest etterspurte fagfeltet i den moderne verden. Data Scientist blir sett på som den mest sexy jobben i det 21. århundre med fagpersoner fra forskjellige fagområder ønsker å lære og bli en Data Scientist. Apache spiller en avgjørende rolle for enhver datavitusiast, ettersom de trenger tilstrekkelig kunnskap om Apache Hadoop-økosystemet.
Apache Hadoop økosystem
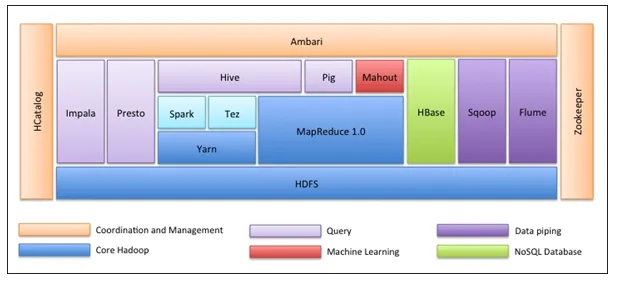
Det aller første er at Hadoop Ecosystem ikke er ett verktøy. Det er ikke et programmeringsspråk eller et enkelt rammeverk. Det er en gruppe verktøy som brukes sammen av forskjellige selskaper i forskjellige domener for flere oppgaver. Vi vil gå gjennom hvert verktøy ett etter ett nedenfor: -
- Apache HDFS (Hadoop Distribution File System) er lagringsenheten til Hadoop som kan lagre strukturerte, semistrukturerte og ustrukturerte data. HDFS har metadata som vedlikeholder loggfilen om lagrede data. Den har to komponenter - NameNode og DataNode.
- Apache Yarn er ressursforhandleren som utfører alle behandlingsaktiviteter som planleggingsoppgaver, tildeling av ressurser, etc. Den har to tjenester - For det første er Resource Manager som planlegger applikasjoner som kjører på toppen av Yarn. For det andre er Node Manager som overvåker ressursutnyttelse .
- Apache Map Reduce er dataprosesseringskomponenten i Hadoop som behandler store datasett ved bruk av distribuert og parallell databehandling basert på Map, Sort and Shuffle og Reduce-funksjoner. Kartfunksjon filtrerer dataene, deretter blir sortering og blanding utført og på slutten Reduser funksjonsaggregater og oppsummerer resultatet.
- Apache Pig brukt mest i ETL. Den har to deler - Pig Latin og Pig runtime. Gris-latin er språket som brukes til databehandling ved hjelp av en spørring, mens grisekjøringstid er utførelsesmiljøet. En linje med griselatin er nesten lik 100 linjer med kartreduseringskode. Prosessen innebærer først å laste inn dataene og deretter gruppere, sortere, filtrere og lagre dem i HDFS.
- Apache Hive bruker et SQL-lignende spørsmål for å analysere data i et distribuert miljø. Den har to komponenter - Hive-kommandolinjen og JDBC / ODBC-serveren og språket som brukes heter HiveQL.
- Apache Mahout er Machine Learning-biblioteket skrevet i Java og brukes til å lage applikasjoner for maskinlæring som klynging, klassifisering eller regresjon. Den har forskjellige algoritmer innebygd for forskjellige brukssaker.
- Apache HBase er en NoSQL-database skrevet i Java som går over Hadoop. Den er bygget basert på Googles BigTable og er i stand til å håndtere alle typer data.
- Apache Sqoop er et verktøy for datainntak som brukes til bulkstrukturert dataoverføring mellom RDBMS og Hadoop.
- Apache Flume er et annet datainntaksverktøy som brukes til semistrukturert og ustrukturert dataoverføring mellom Hadoop og andre datakilder.
- ZooKeeper er koordinatoren som sikrer koordinering mellom ulike verktøy i Hadoop-økosystemet.
- Apache Ambari er en Cluster Manager som forsørger, administrerer Hadoop klynger og overvåker også deres helse og status.
- Apache Tez er et nytt verktøy i Hadoop-økosystemet som akselererer Hadoop's Query-behandling.
- Apache Presto er en open source distribuert SQL spørringsmotor som muliggjør spørsmulighet på tvers av plattformer.
- Apache HCatalog er et metadata- og tabellstyringssystem for Hadoop som muliggjør interoperabilitet på tvers av databehandlingsverktøy. Det hjelper også brukere å velge de beste verktøyene for miljøene sine.
- Apache Spark er den mest brukte og populære rammen blant Data Scientist. Det er et høyhastighets klyngedatasystem som optimaliserer ressursutnyttelsen i tilfelle mange iterative oppgaver. Det gir fleksibilitet både for batchbehandling og sanntids dataanalyse.
Nedenfor er trinnene for å installere Apache
Så langt har vi lært om Apache og hvordan det er nyttig for alle som vil lære Data Science eller Big Data Analytics. Nå vil vi dykke ned og installere apache på vinduer basert på trinnene nedenfor.
- Gå til https://httpd.apache.org/ og klikk på Last ned-lenken under Apache httpd 2.4.38 Utgitt-seksjon.

- Den tar deg til neste side og klikker deretter på Files for Microsoft Windows.
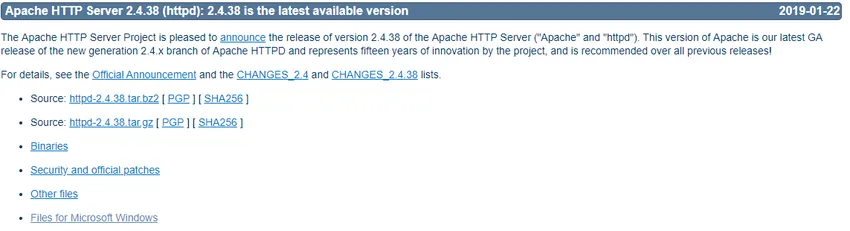
- Klikk på Apache Lounge.

- Du kan laste ned 32-bit eller 64-bit av zip-filen basert på Windows-operativsystemet. Vi vil laste ned 64-biters versjon her. Klikk på den tilsvarende .zip-lenken for å laste ned.

- Nå krever det C ++ Redistributable Visual Studio 2017. Så vi vil laste ned det fra den tilsvarende 32-bit eller 64-bit linken

- Etter at begge filene er lastet ned, vil vi gå ned den nedlastede plasseringen og installere C ++ Redistributable Visual Studio 2017 først. Dobbeltklikk på .exe-filen.

- Merk av for "Jeg er enig" og klikk på Installer.

- Installasjonen av Apache pågår.
- Når den er ferdig, vil du få en melding som denne. Klikk Lukk for å fullføre installasjonen.
- Gå nå til mappen der du laster ned zip-filen Apache. Høyreklikk på den og velg utdrag her.
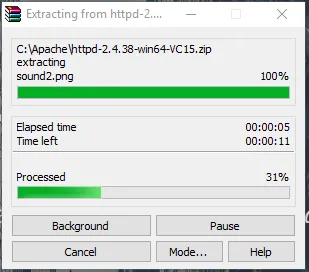
- Nå skal vi opprette en Apache24-mappe. Kopier denne mappen til C-stasjonen, så legger vi til en bane til systemmiljøvariabler.
Gå til Systemegenskaper -> Avansert-fane -> Klikk på Miljøvariabler-knappen nedenfor.
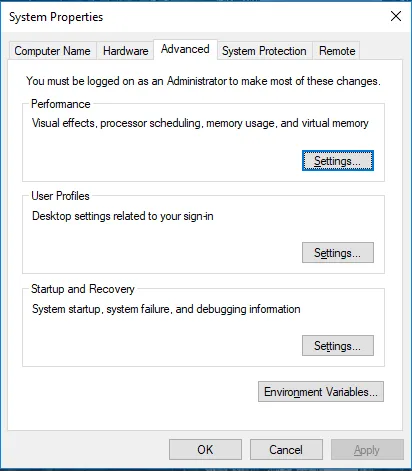
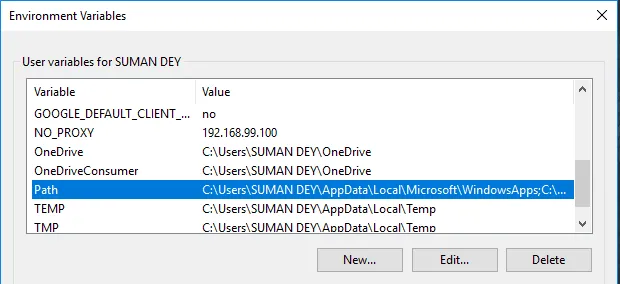
- Finn banen og klikk Rediger i variabler.
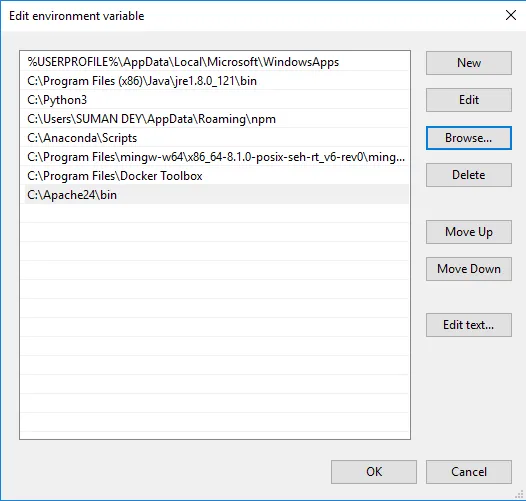
- Klikk Bla gjennom -> Gå til C-stasjonen Apache24-mappen -> Velg søppelkasse-mappen -> Klikk på OK.
- Vi installerer Apache som en Windows-tjeneste. Kjør ledetekst som administrator. Skriv inn httpd –k installer og trykk enter.
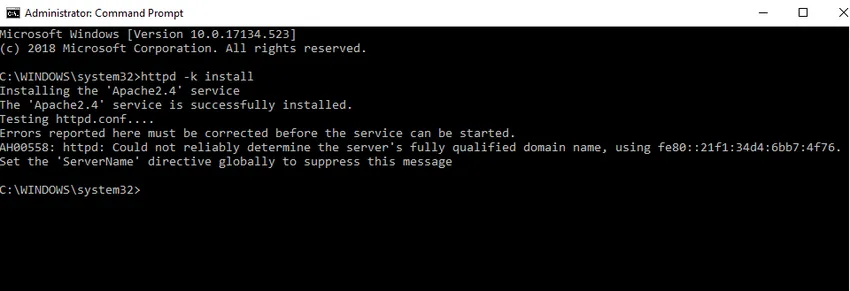
- Vi sjekker installasjonen av Apache-tjenesten. Klikk på Windows-ikonet og skriv inn tjenester. Klikk på Tjenester-appen og finn service med navnet Apache24.

- For å starte Apache-serveren, høyreklikk på den og klikk på start. Status endres til 'Running'.
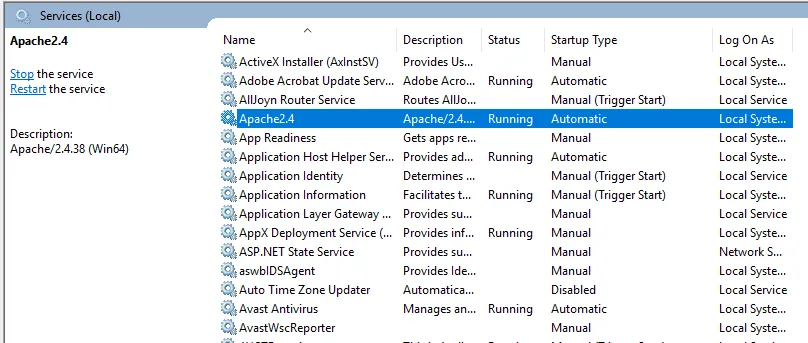
- Vi kan teste med en nettleser. Åpne en nettleser og naviger til http: // localhost og trykk enter. En melding om "Det fungerer!" vises for å bekrefte vellykket installasjon av Apache.
Anbefalte artikler
Dette har vært en guide for hvordan du installerer Apache. Her har vi diskutert instruksjonene og forskjellige trinn for å installere Apache. Du kan også se på følgende artikkel for å lære mer -
- Spørsmål om Apache-intervju
- Apache Spark vs Apache Flink
- Apache Hadoop vs Apache Spark
- Apache Kafka vs Flume
- Kafka vs Kinesis | Topp forskjeller