

Introduksjon til Decision Tree Algoritm
Når vi har fått et problem å løse, som enten er et klassifiserings- eller et regresjonsproblem, er beslutnings-tre-algoritmen en av de mest populære algoritmene som brukes til å bygge klassifiserings- og regresjonsmodeller. De faller inn under kategorien veiledet læring, dvs. data som er merket.
Hva er Decision Tree Algorithm?
Decision Tree Algorithm er en overvåket maskinlæringsalgoritme der data kontinuerlig blir delt på hver rad basert på visse regler til det endelige resultatet blir generert. La oss ta et eksempel, anta at du åpner et kjøpesenter, og selvfølgelig vil du at det skal vokse i virksomhet med tiden. Så for den saks skyld vil du kreve tilbakevendende kunder pluss nye kunder i kjøpesenteret. For dette vil du utarbeide forskjellige forretnings- og markedsføringsstrategier som å sende e-post til potensielle kunder; opprette tilbud og tilbud, målrette mot nye kunder osv. Men hvordan vet vi hvem som er de potensielle kundene? Med andre ord, hvordan klassifiserer vi kategorien til kundene? Som at noen kunder vil besøke en gang i uken, og andre vil besøke en eller to ganger i løpet av en måned, eller noen vil besøke om et kvarter. Så avgjørelsestrær er en slik klassifiseringsalgoritme som vil klassifisere resultatene i grupper til det ikke er mer likhet igjen.
På denne måten går beslutningstreet ned i et trestrukturert format. Hovedkomponentene i et beslutnings tre er:
- Beslutningsnoder, som er hvor dataene er delt eller si, det er et sted for attributtet.
- Decision Link, som representerer en regel.
- Beslutningsblad, som er de endelige resultatene.

Arbeidet med en beslutnings tre-algoritme
Det er mange trinn som er involvert i arbeidet med et beslutnings tre:
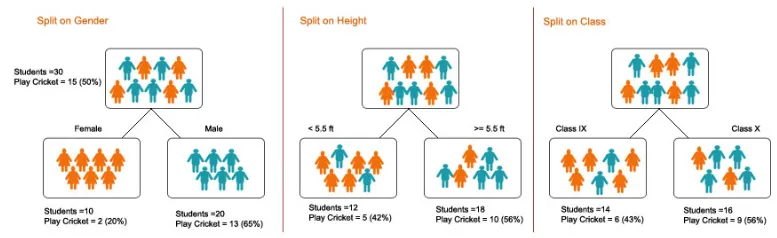
1. Splitting - Det er prosessen med partisjonering av data i delmengder. Splitting kan gjøres på forskjellige faktorer som vist nedenfor, dvs. på kjønnsbasis, høydebasis eller basert på klasse.
2. Beskjæring - Det er prosessen med å forkorte grenene til avgjørelsestreet, og dermed begrense tredybden
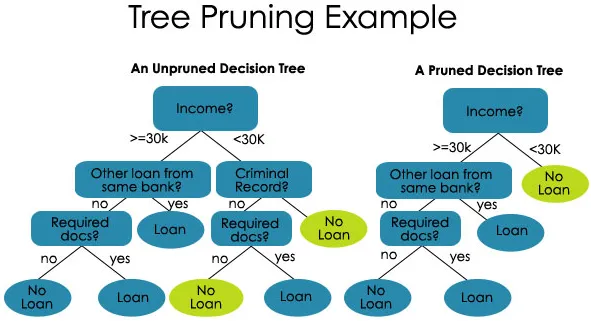
Beskjæring er også av to typer:
- Forhåndsbeskjæring - Her slutter vi å dyrke treet når vi ikke finner noen statistisk signifikant sammenheng mellom attributtene og klassen på noen bestemt nod.
- Etter beskjæring - For å kunne beskjære, må vi validere ytelsen til testsettmodellen og deretter kutte grenene som er et resultat av overmontering av støy fra treningssettet.
3. Valg av tre - Det tredje trinnet er prosessen med å finne det minste treet som passer til dataene.
Eksempler og illustrasjon på konstruksjon av et beslutnings tre
Nå, som vi har lært prinsippene for et beslutnings tre. La oss forstå og illustrere dette ved hjelp av et eksempel.
La oss si at du vil spille cricket på en bestemt dag (for eksempel lørdag). Hva er faktorene som er involvert som vil avgjøre om stykket kommer til å skje eller ikke?
Det er tydelig at hovedfaktoren er klimaet, ingen andre faktorer har så stor sannsynlighet for like mye klima for lekeavbruddet.
Vi har samlet dataene fra de siste 10 dagene som presenteres nedenfor:
| Dag | Vær | Temperatur | Luftfuktighet | Vind | Spille? |
| 1 | Skyet | Varmt | Høy | Svak | Ja |
| 2 | Solfylt | Varmt | Høy | Svak | Nei |
| 3 | Solfylt | Mild | Vanlig | Sterk | Ja |
| 4 | Rainy | Mild | Høy | Sterk | Nei |
| 5 | Skyet | Mild | Høy | Sterk | Ja |
| 6 | Rainy | Kul | Vanlig | Sterk | Nei |
| 7 | Rainy | Mild | Høy | Svak | Ja |
| 8 | Solfylt | Varmt | Høy | Sterk | Nei |
| 9 | Skyet | Varmt | Vanlig | Svak | Ja |
| 10 | Rainy | Mild | Høy | Sterk | Nei |
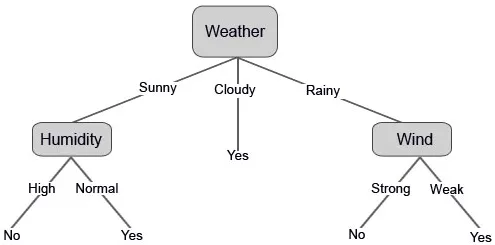
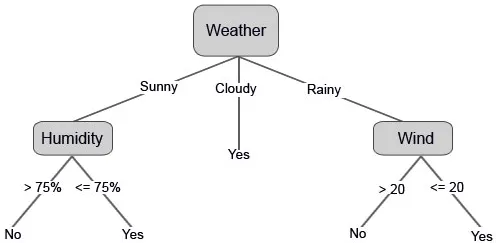
La oss nå konstruere avgjørelsestreet vårt basert på dataene vi har fått. Så vi har delt avgjørelsestreet i to nivåer, det første er basert på attributtet “Vær” og den andre raden er basert på “Fuktighet” og “Vind”. Bildene nedenfor illustrerer et lært beslutningstre.
Vi kan også stille noen terskelverdier hvis funksjonene er kontinuerlige.
Hva er entropi i Decision Tree Algoritm?
Med enkle ord er entropi et mål på hvor uordnede dataene dine er. Selv om du kanskje har hørt dette begrepet i matematikk- eller fysikkursene, er det det samme her.
Årsaken til at Entropy brukes i beslutnings-treet er fordi det endelige målet i beslutnings-treet er å gruppere lignende datagrupper i lignende klasser, dvs. å rydde dataene.
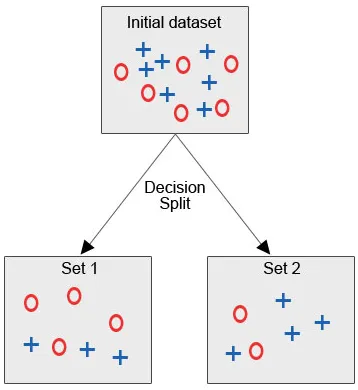
La oss se bildet nedenfor, der vi har det opprinnelige datasettet, og vi er pålagt å bruke beslutnings-tre-algoritmen for å gruppere de samme datapunktene i en kategori.
Etter beslutningsdelingen, som vi tydelig kan se, faller de fleste røde sirkler under en klasse, mens de fleste av de blå korsene faller inn under en annen klasse. Derfor ble en beslutning å klassifisere attributtene som kunne være basert på forskjellige faktorer.
La oss prøve å gjøre noe matematikk her:
La oss si at vi har "N" sett for varen og disse elementene faller inn i to kategorier, og nå for å gruppere dataene basert på etiketter, introduserer vi forholdet:
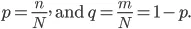
Entropien til vårt sett er gitt av følgende ligning:
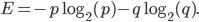
La oss sjekke grafen for den gitte ligningen:
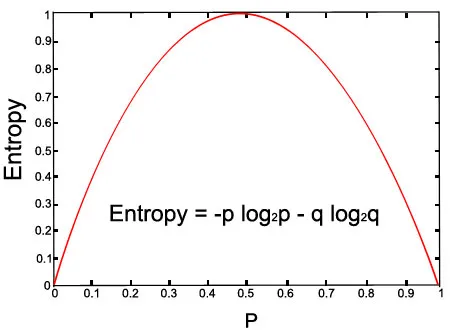
Over bilde (med p = 0, 5 og q = 0, 5)
Fordeler
1. Et beslutnings tre er enkelt å forstå, og når det først er forstått, kan vi konstruere det.
2. Vi kan implementere et beslutnings tre på både numeriske og kategoriske data.
3. Decision Tree er bevist å være en robust modell med lovende resultater.
4. De er også tidseffektive med store data.
5. Det krever mindre krefter for trening av dataene.
ulemper
1. Instabilitet - Bare hvis informasjonen er presis og nøyaktig, vil beslutnings-treet gi lovende resultater. Selv om det er en liten endring i inputdataene, kan det føre til store endringer i treet.
2. Kompleksitet - Hvis datasettet er stort med mange kolonner og rader, er det en veldig kompleks oppgave å designe et beslutnings tre med mange grener.
3. Kostnader - Noen ganger forblir kostnad også en hovedfaktor fordi når man er pålagt å konstruere et komplekst beslutnings tre, krever det avansert kunnskap innen kvantitativ og statistisk analyse.
Konklusjon
I denne artikkelen lærte vi om beslutnings trealgoritmen og hvordan du konstruerer en. Vi så også den store rollen som Entropy spiller i beslutnings-tre-algoritmen, og til slutt så vi fordelene og ulempene ved beslutnings-treet.
Anbefalte artikler
Dette har vært en guide til Decision Tree Algorithm. Her diskuterte vi rollen spilt av Entropy, Working, Advantages and Disruption. Du kan også gå gjennom andre foreslåtte artikler for å lære mer -
- Viktige metoder for utvinning av data
- Hva er webapplikasjon?
- Veiledning for hva er datavitenskap?
- Dataanalytiker intervju spørsmål
- Anvendelse av beslutningstreet i datamining