

Hva er Big Data og Hadoop?
Data vokser eksponentielt hver dag, og med slike voksende data kommer behovet for å bruke disse dataene. Som i eldre dager pleide vi å ha disketter for å lagre data, og dataoverføringen var også treg, men i dag er disse utilstrekkelige og skylagring brukes fordi vi har terabyte med data. I dagens verden har vi sosiale medier som bidrar høyest i dataveksten. Det består av folks atferd, tankesett og flere andre aspekter. Det sies at 300 minutter med video lastes opp på YouTube hvert minutt, over 20 millioner bilder lastes opp i Facebook og mange andre. Dessuten er det ingen riktig struktur for dataene som lastes opp, noe som er den største utfordringen for å behandle disse dataene.
Ettersom enorme data genereres med høy hastighet, klarte ikke tradisjonelle RDBMS-systemer å håndtere en så hurtig vekst. Dessuten er de heller ikke i stand til å håndtere ustrukturerte data. Det ble veldig vanskelig å håndtere en så enorm mengde heterogene data som vokste raskt og å behandle disse dataene med høy prosesseringshastighet. Dermed kom et behov for et slikt system som er i stand til å håndtere store datasett effektivt. For å løse scenariet kom Hadoop til. HDFS er komponenten i Hadoop som adresserte lagringsproblemer for det store datasettet ved å bruke distribuert lagring mens YARN er komponenten som adresserte prosesseringsproblemet som reduserer behandlingstiden drastisk.
Hadoop er et programvare med åpen kildekode for lagring og prosessering av store datasett ved bruk av en distribuert stor klynge med maskinvare. Den ble utviklet av Doug Cutting og Michael J. Cafarella og lisensiert under Apache. Det er skrevet med Java og ble utviklet basert på papiret skrevet av Google om MapReduce-systemet, og det bruker konsepter om funksjonell programmering. Den er pålitelig, økonomisk fleksibel og skalerbar.
Kjernekomponentene i Hadoop
Kjernekomponentene til Hadoop er som følger
-
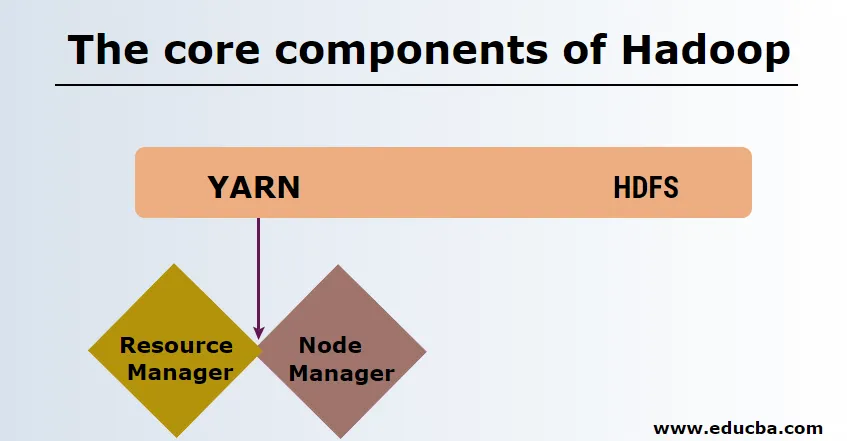
HDFS
HDFS eller Hadoop Distribuert filsystem har Namenode og datanode. Namenode er hovednoden som kjører master-demonet, og den administrerer dataknodene og holder oversikt over alle operasjoner. Datanoder er slavene der dataene faktisk er lagret.
-
YARN
YARN består av to hovedkomponenter:
1. ResourceManager: Den kjører på hovednoden og administrerer alle ressurser og planlegger alle applikasjoner. Den har Scheduler & ApplicationManager.
2. NodeManager: Den kjører på hver slaveknute og er ansvarlig for å administrere containere og overvåke ressursutnyttelse.
Flere komponenter av Hadoop
Det er flere komponenter i Hadoop som grisen, bikuben, sqoop, flume, mahout, oozie, dyrepasser, HBase, etc.
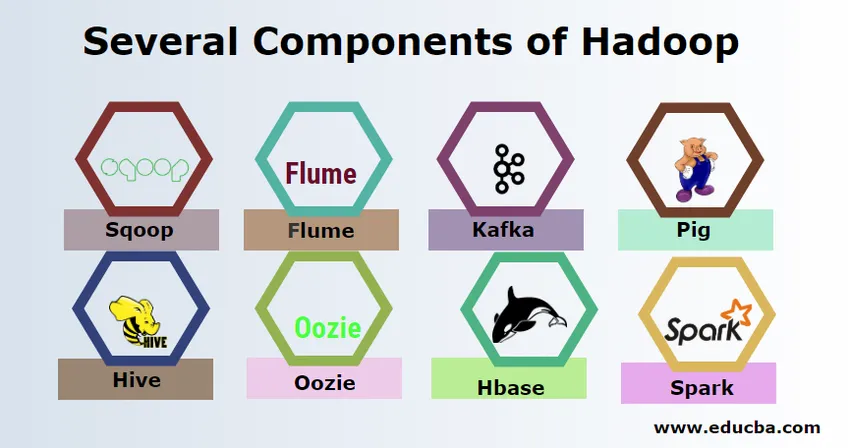
- Sqoop - Den brukes til å importere og eksportere data fra RDBMS til Hadoop og omvendt.
- Flume - Det brukes til å trekke sanntidsdata inn i Hadoop.
- Kafka - Det er et meldingssystem som brukes til å rute sanntidsdata til Hadoop.
- Pig - Det brukes som skriptspråk for databehandling.
- Hive - Det er et rammeverk for datavarehus som bygger på HDFS, slik at brukere som er kjent med SQL, kan utføre spørsmål for å få dataene. Disse spørsmålene kalles HiveQL.
- Oozie - Det brukes til å planlegge arbeidsflyten av jobber som skal kjøres på spesifiserte hendelser eller tid.
- Hbase - Det er ingen SQL-database gitt som en del av Apache Hadoop.
- Spark - Den brukes til å utføre prosessering i minnet som er mye raskere enn Hadoop kart redusere.
Hadoop Providers
Det er mange selskaper som tilbyr Hadoop-distribusjoner. Nedenfor er noen få beste leverandører for Hadoop:
- Cloudera
- Hortonworks
- MapR
Det er få forutsetninger for å lære Hadoop. Tidligere erfaring med Java og skriptspråk er nødvendig. Selv om Hadoop allerede har egne programmeringsspråk på høyt nivå som gris og bikube som genererer backend-koden for videre prosessering, er det fremdeles mulig å lage et eget kartreduserende program som et hvilket som helst programmeringsspråk som Ruby, Python, Perl og til og med C-programmering.
Bigdata og Hadoop er etterspurt i dagens marked. Dette kommer til å øke mer de kommende dagene. Mange organisasjoner har allerede flyttet inn i Hadoop, og de som ikke har planer om å flytte snart. Det foreligger en aktuell rapport om at store selskaper har begynt å investere i big data-analyse. Big data marketing prognose er alltid i oppadgående trend, og det er overhode ikke en kortvarig tilstand. Bortsett fra alle disse jobbene i Hadoop og big data tilbyr alltid høy lønn sammenlignet med andre teknologier.
Topp Big Data og Hadoop selskaper
Nedenfor er noen få toppbedrifter som bruker flest antall Hadoop-ressurser.
- Yahoo
- Amazon
- Royal Bank of Scotland
- British Airways
- Expedia
- Walmart
Det er mange selskaper som bruker big data applikasjoner. Disse er:
-
Nokia
Den bruker Cloudera og Hadoop-komponenter som HDFS, HBase, Sqoop, Scribe for applikasjonen. Den brukte brukerdata effektivt for å forstå og forbedre brukerens opplevelse. Den bruker databehandling og komplekse analyser for å bygge kartet med prediktiv trafikk og lagdelte høydemodeller.
-
SAS
Det har samarbeidet med Hadoop for å hjelpe dataforskere med å få bedre innsikt ved å tilby et miljø som gir visuell og interaktiv opplevelse og dermed hjelper til med å utforske nye trender. De analytiske programmene henter meningsfull innsikt fra data, og in-memory-teknologien hjelper raskere tilgang til data.
Det er også mange andre selskaper som bruker big data-plattformer for forskjellige analyser. Dette er flydata-analyse av black box i luftfartsindustrien, de forskjellige analysene i aksjemarkedet, etc.
Fordelene med Haddop
Nedenfor er noen av fordelene med Hadoop
- Skalerbar - I motsetning til tradisjonelle RDBMS er det en svært skalerbar plattform da den kan lagre store datasett i distribuerte klynger over råvaremaskinvare som opererer parallelt.
- Kostnadseffektiv - Kostnaden var for høy for at RDBMS kunne lagre data som er lettet i Hadoop.
- Rask og fleksibel - Den tilbyr data som du vil ha tilgang til på en rask måte via det distribuerte filsystemet. Det tilbyr også å oppnå forretningsinnsikt fra semistrukturerte og ustrukturerte data.
- Feiltolerant - Når data sendes til en node, kopieres de samme dataene til andre noder som kan nås i tilfelle feil i den første noden.
Konklusjon - hva er Big Data og Hadoop
Data vokser kontinuerlig, og det vil derfor alltid være behov for big data og Hadoop for å være fornuftige ut fra disse dataene. Av denne grunn vil fagfolk med Hadoop-ferdigheter alltid finne gode muligheter de kommende dagene og kan være en viktig ressurs for en organisasjon som styrker virksomheten og deres karriere.
Anbefalte artikler
Dette har vært en guide for hva som er Big Data og Hadoop. Her har vi diskutert de grunnleggende konseptene og komponentene til Big Data og Hadoop. Du kan også se på følgende artikkel for å lære mer -
- Eksempler på Big Data Analytics
- Bruk av Hadoop
- Veiledning for datavisualisering
- Hva er Big data analytics?